NoSQL 数据建模技术
Posted onNoSQL 数据建模技术
酷壳 – CoolShell.cn
享受编程和技术所带来的快乐 – http://coolshell.cn
NoSQL 数据建模技术
2012年5月15日 陈皓 发表评论 阅读评论 30,135 人阅读
全文译自墙外文章“NoSQL Data Modeling Techniques”,译得不好,还请见谅。这篇文章看完之后,你可能会对NoSQL的数据结构会有些感觉。我的感觉是,关系型数据库想把一致性,完整性,索引,CRUD都干好,NoSQL只干某一种事,但是牺牲了很多别的东西。总体来说,我觉得NoSQL更适合做Cache。下面是正文——
NoSQL 数据库经常被用作很多非功能性的地方,如,扩展性,性能和一致性的地方。这些NoSQL的特性在理论和实践中都正在被大众广泛地研究着,研究的热点正是那些和性能分布式相关的非功能性的东西,我们都知道 CAP 理论被很好地应用于了 NoSQL 系统中(陈皓注:CAP即,一致性(Consistency), 可用性(Availability), 分区容忍性(Partition tolerance),在分布式系统中,这三个要素最多只能同时实现两个,而NoSQL一般放弃的是一致性)。但在另一方面,NoSQL的数据建模技术却因为缺乏像关系型数据库那样的基础理论没有被世人很好地研究。这篇文章从数据建模方面对NoSQL家族进行了比较,并讨论几个常见的数据建模技术。
要开始讨论数据建模技术,我们不得不或多或少地先系统地看一下NoSQL数据模型的成长的趋势,以此我们可以了解一些他们内在的联系。下图是NoSQL家族的进化图,我们可以看到这样的进化:Key-Value时代,BigTable时代,Document时代,全文搜索时代,和Graph数据库时代:(陈皓注:注意图中SQL说的那句话,NoSQL再这样发展下去就是SQL了,哈哈。)
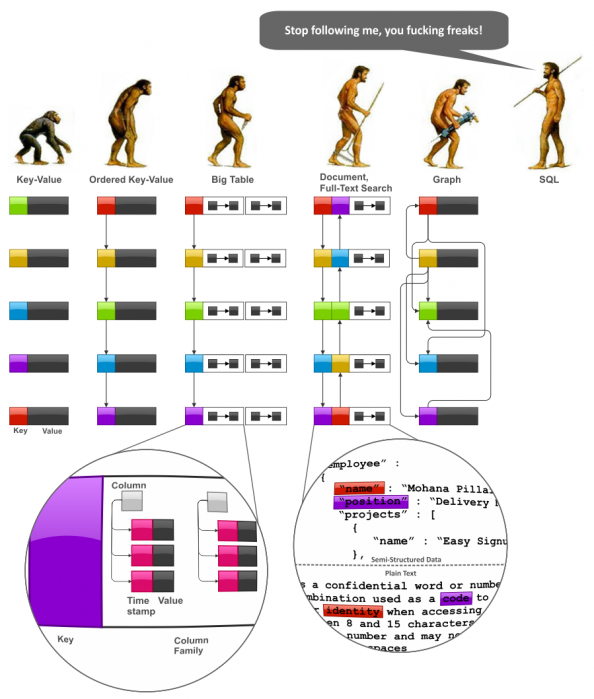
首先,我们需要注意的是SQL和关系型数据模型已存在了很长的时间,这种面向用户的自然性意味着:
- 最终用户一般更感兴趣于数据的聚合显示,而不是分离的数据,这主要通过SQL来完成。
- 我们无法通过人手工控制数据的并发性,完整性,一致性,或是数据类型校验这些东西的。这就是为什么SQL需要在事务,二维表结构(schema)和外表联合上做很多事。
另一方面,SQL可以让软件应用程序在很多情况下不需要关心数据库的数据聚合,和数据完整性和有效性进行控制。而如果我们去除了数据一致性,完整性这些东西,会对性能和分布存储有着重的帮助。正因为如此,我们才有数据模型的进化:
Key-Value 键值对存储是非常简单而强大的。下面的很多技术基本上都是基于这个技术开始发展的。但是,Key-Value有一个非常致命的问题,那就是如果我们需要查找一段范围内的key。(陈皓注:学过hash-table数据结构的人都应该知道,hash-table是非序列容器,其并不像数组,链接,队列这些有序容器,我们可以控制数据存储的顺序)。于是,有序键值 (Ordered Key-Value) 数据模型被设计出来解决这一限制,来从根本上提高数据集的问题。
Ordered Key-Value 有序键值模型也非常强大,但是,其也没有对Value提供某种数据模型。通常来说,Value的模型可以由应用负责解析和存取。这种很不方便,于是出现了 BigTable类型的数据库,这个数据模型其实就是map里有map,map里再套map,一层一层套下去,也就是层层嵌套的key-value(value里又是一个key-value),这种数据库的Value主要通过“列族”(column families),列,和时间戳来控制版本。(陈皓注:关于时间戳来对数据的版本控制主要是解决数据存储并发问题,也就是所谓的乐观锁,详见《多版本并发控制(MVCC)在分布式系统中的应用》)
Document databases 文档数据库 改进了 BigTable 模型,并提供了两个有意义的改善。第一个是允许Value中有主观的模式(scheme),而不是map套map。第二个是索引。 Full Text Search Engines 全文搜索引擎可以被看作是文档数据库的一个变种,他们可以提供灵活的可变的数据模式(scheme)以及自动索引。他们之间的不同点主要是,文档数据库用字段名做索引,而全文搜索引擎用字段值做索引。
Graph data models 图式数据库 可以被认为是这个进化过程中从 Ordered Key-Value 数据库发展过来的一个分支。图式数据库允许构建议图结构的数据模型。它和文档数据库有关系的原因是,它的很多实现允许value可以是一个map或是一个document。
NoSQL 数据模型摘要
本文剩下的章节将向你介绍数据建模的技术实现和相关模式。但是,在介绍这些技术之前,先来一段序言:
NoSQL 数据模型设计一般从业务应用的具体数据查询入手,而不是数据间的关系:
关系型的数据模型基本上是分析数据间的结构和关系。其设计理念是: ”What answers do I have?”**
NoSQL 数据模型基本上是从应用对数据的存取方式入手,如:我需要支持某种数据查询。其设计理念是 ”What questions do I have?”
NoSQL 数据模型设计比关系型数据库需要对数据结构和算法的更深的了解。在这篇文章中我会和大家说那些尽人皆知的数据结构,这些数据结构并不只是被NoSQL使用,但是对于NoSQL的数据模型却非常有帮助。
数据冗余和反规格化是一等公民。
关系型数据库对于处理层级数据和图式数据非常的不方便。NoSQL用来解决图式数据明显是一个非常好的解决方案,几乎所有的NoSQL数据库可以很强地解决此类问题。这就是为什么这篇文章专门拿出一章来说明层级数据模型。 下面是NoSQL的分类表,也是我用来写这篇文章时做实践的产品:
Key-Value 存储: Oracle Coherence, Redis, Kyoto Cabinet
- 类BigTable存储: Apache HBase, Apache Cassandra
- 文档数据库: MongoDB, CouchDB
- 全文索引: Apache Lucene, Apache Solr
- 图数据库: neo4j, FlockDB
概念技术 Conceptual Techniques
这一节主要介绍NoSQL数据模型的基本原则。
(1) 反规格化 Denormalization
反规格化 Denormalization 可以被认为是把相同的数据拷贝到不同的文档或是表中,这样就可以简化和优化查询,或是正好适合用户的某中特别的数据模型。这篇文章中所说的绝大多数技术都或多或少地导向了这一技术。
总体来说,反规格化需要权衡下面这些东西:
查询数据量 /查询IO VS 总数据量。使用反规格化,一方面可以把一条查询语句所需要的所有数据组合起来放到一个地方存储。这意味着,其它不同不同查询所需要的相同的数据,需要放在别不同的地方。因此,这产生了很多冗余的数据,从而导致了数据量的增大。
处理复杂度 VS 总数据量. 在符合范式的数据模式上进行表连接的查询,很显然会增加了查询处理的复杂度,尤其对于分布式系统来说更是。反规格化的数据模型允许我们以方便查询的方式来存构造数据结构以简化查询复杂度。
适用性: Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库。
(2) 聚合 Aggregates
所有类型的NoSQL数据库都会提供灵活的Schema(数据结构,对数据格式的限制):
Key-Value Stores 和 Graph Databases 基本上来说不会Value的形式,所以Value可以是任意格式。这样一来,这使得我们可以任意组合一个业务实体的keys。比如,我们有一个用户帐号的业务实体,其可以被如下这些key组合起来: UserID_name, UserID_email, UserID_messages 等等。如果一个用户没有email或message,那么相应也不会有这样的记录。
BigTable 模型通过列集合来支持灵活的Schema,我们称之为列族(column family)。BigTable还可以在同一记录上出现不同的版本(通过时间戳)。
Document databases 文档数据库是一种层级式的“去Schema”的存储,虽然有些这样的数据库允许检验需要保存的数据是否满足某种Schema。
灵活的Schema允许你可以用一种嵌套式的内部数据方式来存储一组有关联的业务实体(陈皓注:类似于JSON这样的数据封装格式)。这样可以为我们带来两个好处。
最小化“一对多”关系——可以通过嵌套式的方式来存储实体,这样可以少一些表联结。
可以让内部技术上的数据存储更接近于业务实体,特别是那种混合式的业务实体。可能存于一个文档集或是一张表中。 下图示意了这两种好处。图中描给了电子商务中的商品模型(陈皓注:我记得我在“挑战无处不在”一文中说到过电商中产品分类数据库设计的挑战)
首先,所有的商品Product都会有一个ID,Price 和 Description。
然后,我们可以知道不同的类型的商品会有不同的属性。比如,作者是书的属性,长度是牛仔裤的属性。其些属性可能是“一对多”或是“多对多”的关系,如:唱片中的曲目。
接下来,我们知道,某些业务实体不可能使用固定的类型。如:牛仔裤的属性并不是所有的牌子都有的,而且,有些名牌还会搞非常特别的属性。
对于关系型数据库来说,要设计这样的数据模型并不简单,而且设计出来的绝对离优雅很远很远。而我们NoSQL中灵活的Schema允许你使用一个聚合 Aggregate (product) 可以建出所有不同种类的商品和他们的不同的属性:

Entity Aggregation
上图中我们可以比较关系型数据库和NoSQL的差别。但是我们可以看到在数据更新上,非规格化的数据存储在性能和一致性上会有很大的影响,这就是我们需要重点注意和不得不牺牲的地方。
适用性: Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库。
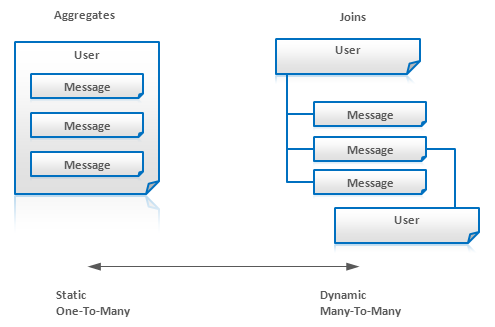
(3) 应用层联结 Application Side Joins
表联结基本上不被NoSQL支持。正如我们前面所说的,NoSQL是“面向问题”而不是“面向答案”的,不支持表联结就是“面向问题”的后果。表的联结是在设计时被构造出来的,而不是在执行时建造出来的。所以,表联结在运行时是有很大开销的(陈皓注:搞过SQL表联结的都知道笛卡尔积是什么东西,大可以在参看以前酷壳的“图解数据库表Joins”),但是在使用了 Denormalization 和 Aggregates 技术后,我们基本不用进行表联结,如:你们使用嵌套式的数据实体。当然,如果你需要联结数据,你需要在应用层完成这个事。下面是几个主要的Use Case:
多对多的数据实体关系——经常需要被连接或联结。
聚合 Aggregates 并不适用于数据字段经常被改变的情况。对此,我们需要把那些经常被改变的字段分到另外的表中,而在查询时我们需要联结数据。例如,我们有个Message系统可以有一个User实体,其包括了一个内嵌的Message实体。但是,如果用户不断在附加 message,那么,最好把message拆分到另一个独立的实体,但在查询时联结这User和Message这两个实体。如下图:
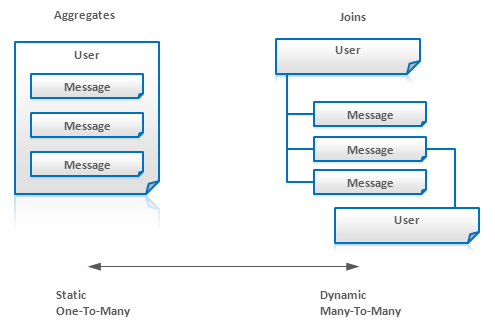
适用性: Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库, Graph Databases 图数据库。
通用建模技术 General Modeling Techniques
在本书中,我们将讨论NoSQL中各种不同的通用的数据建模技术。
(4) 原子聚合 Atomic Aggregates
很多NoSQL的数据库(并不是所有)在事务处理上都是短板。在某些情况下,他们可以通过分布式锁技术或是应用层管理的MVCC技术来实现其事务性(陈皓注:可参看本站的“多版本并发控制(MVCC)在分布式系统中的应用”)但是,通常来说只能使用聚合Aggregates技术来保证一些ACID原则。
这就是为什么我们的关系型数据库需要有强大的事务处理机制——因为关系型数据库的数据是被规格化存放在了不同的地方。所以,Aggregates聚合允许我们把一个业务实体存成一个文档、存成一行,存成一个key-value,这样就可以原子式的更新了:
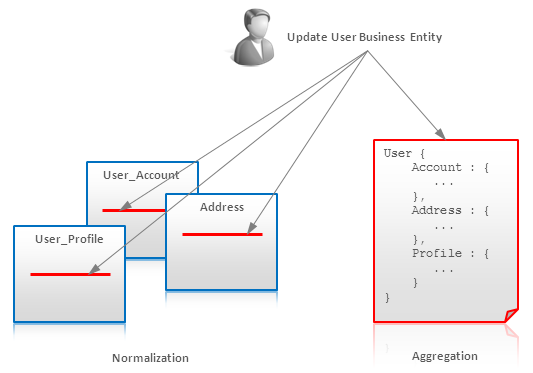
当然,原子聚合 Atomic Aggregates 这种数据模型并不能实现完全意义上的事务处理,但是如果支持原子性,锁,或 test-and-set 指令,那么, Atomic Aggregates 是可以适用的。
**适用性: **Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库。
(5) 可枚举键 Enumerable Keys
也许,对于无顺序的Key-Value最大的好处是业务实体可以被容易地hash以分区在多个服务器上。而排序了的key会把事情搞复杂,但是有些时候,一个应用能从排序key中获得很多好处,就算是数据库本身不提供这个功能。让我们来思考下email消息的数据模型:
- 一些NoSQL的数据库提供原子计数器以允许生一些连续的ID。在这种情况下,我们可以使用 userID_messageID 来做为一个组合key。如果我们知道最新的message ID,就可以知道前一个message,也可能知道再前面和后面的Message。
- Messages可以被打包。比如,每天的邮件包。这样,我们就可以对邮件按指定的时间段来遍历。
**适用性: **Key-Value Store 键值对数据库。
(6) 降维 Dimensionality Reduction
Dimensionality Reduction 降维是一种技术可以允许把一个多维的数据映射成一个Key-Value或是其它非多给的数据模型。
传统的地理位置信息系统使用一些如“四分树QuadTree” 或 “R-Tree” 来做地理位置索引。这些数据结构的内容需要被在适当的位置更新,并且,如果数据量很大的话,操作成本会很高。另一个方法是我们可以遍历一个二维的数据结构并把其扁平化成一个列表。一个众所周知的例子是Geohash(地理哈希)。一个Geohash使用“之字形”的路线扫描一个2维的空间,而且遍历中的移动可以被简单地用0和1来表示其方向,然后在移动的过程中产生0/1串。下图展示了这一算法:(陈皓注:先把地图分成四份,经度为第一位,纬度为第二位,于是左边的经度是0,右边的是1,纬度也一样,上面是为1,下面的为0,这样,经纬度就可以组合成01,11,00,10这四个值,其标识了四块区域,我们可以如此不断的递归地对每个区域进行四分,然后可以得到一串1和0组成的字串,然后使用0-9,b-z 去掉(去掉a, i, l, o)这32个字母进行base32编码得到一个8个长度的编码,这就是Geohash的算法)

Geohash的最强大的功能是使用简单的位操作就可以知道两个区域间的距离,就像图中所示(陈皓:proximity框着的那两个,这个很像IP地址了)。Geohash把一个二维的坐标生生地变成了一个一维的数据模型,这就是降维技术。BigTable的降维技术参看到文章后面的 [6.1]。更多的关于Geohash和其它技术可以参看 [6.2] 和 [6.3]。
**适用性:** Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库。
(7) 索引表 Index Table
Index Table 索引表是一个非常直白的技术,其可以你在不支持索引的数据库中得到索引的好处。BigTable是这类最重要的数据库。这需要我们维护一个有相应存取模式的特别表。例如,我们有一个主表存着用户帐号,其可以被UserID存取。某查询需要查出某个城市里所有的用户,于是我们可以加入一张表,这张表用城市做主键,所有和这个城市相关的UserID是其Value,如下所示:
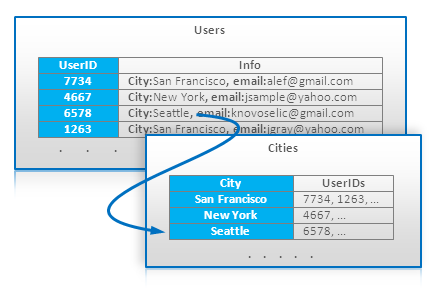
可见,城市索引表的需要和对主表用户表保持一致性,因此,主表的每一个更新可能需要对索引表进行更新,不然就是一个批处理更新。无论哪个方式,这都会损伤一些性能,因为需要保持一致性。
Index Table 索引表可以被认为是关系型数据库中的视图的等价物。
适用性: BigTable 数据库。
(8) 键组合索引 Composite Key Index
Composite key 键组合是一个很常用的技术,对此,当我们的数据库支持键排序时能得到极大的好处。Composite key组合键的拼接成为第二排序字段可以让你构建出一种多维索引,这很像我们之前说过的 Dimensionality Reduction 降维技术。例如,我们需要存取用户统计。如果我们需要根据不同的地区来统计用户的分布情况,我们可以把Key设计成这样的格式 (State:City:UserID),这样一来,就使得我们可以通过State到City来按组遍历用户,特别是我们的NoSQL数据库支持在key上按区查询(如:BigTable类的系统): 1
2 SELECT
Values
WHERE
state=
"CA:/*"
SELECT
Values
WHERE
city=
"CA:San Francisco/*"
 Composite Key Index
Composite Key Index
**适用性:**BigTable 数据库。
(9) 键组合聚合 Aggregation with Composite Keys
Composite keys 键组合技术并不仅仅可以用来做索引,同样可以用来区分不用的类型的数据以支持数据分组。考虑一个例子,我们有一个海量的日志数组,这个日志记录了互联网上的用户的访问来源。我们需要计算从某一网站过来的独立访客的数量,在关系型数据库中,我们可能需要下面这样的SQL查询语句: 1SELECT
count
(
distinct
(user_id))
FROM
clicks
GROUP
BY
site
我们可以在NoSQL中建立如下的数据模型:
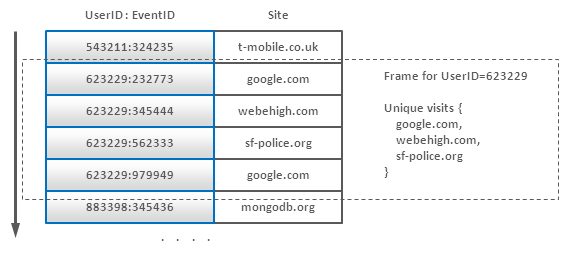
这样,我们就可以把数据按UserID来排序,我们就可以很容易把同一个用户的数据(一个用户并不会产生太多的event)进行处理,去掉那些重复的站点(使用hash table或是别的什么)。另一个可选的技术是,我们可以对每一个用户建立一个数据实体,然后把其站点来源追加到这个数据实体中,当然,这样一来,数据的更新在性能相比之下会有一定损失。
**适用性:** Ordered Key-Value Store 排序键值对数据库, BigTable风格的数据库。
(10) 反转搜索 Inverted Search – 直接聚合 Direct Aggregation
这个技术更多的是数据处理技术,而不是数据建模技术。尽管如此,这个技术还是会影响数据模型。这个技术最主要的想法是使用一个索引来找到满足某条件的数据,但是把数据聚合起需要使用全文搜索。还是让我们来说一个示例。还是用上面那个例子,我们有很多的日志,其中包括互联网用户和他们的访问来源。让我们假定每条记录都有一个UserID,还有用户的种类 (Men, Women, Bloggers, 等),以及用户所在的城市,和访问过的站点。我们要干的事是,为每个用户种类找到满足某些条件(访问源,所在城市,等)的的独立用户。
很明显,我们需要搜索那些满足条件的用户,如果我们使用反转搜索,这会让我们把这事干得很容易,如: {Category -> [user IDs]} 或 {Site -> [user IDs]}。使用这样的索引, 我们可以取两个或多个UserID要的交集或并集(这个事很容易干,而且可以干得很快,如果这些UserID是排好序的)。但是,我们要按用户种类来生成报表会变得有点麻烦,因为我们用语句可能会像下面这样 1SELECT
count
(
distinct
(user_id)) ...
GROUP
BY
category
但这样的SQL很没有效率,因为category数据太多了。为了应对这个问题,我们可以建立一个直接索引 {UserID -> [Categories]} 然后我们用它来生成报表:
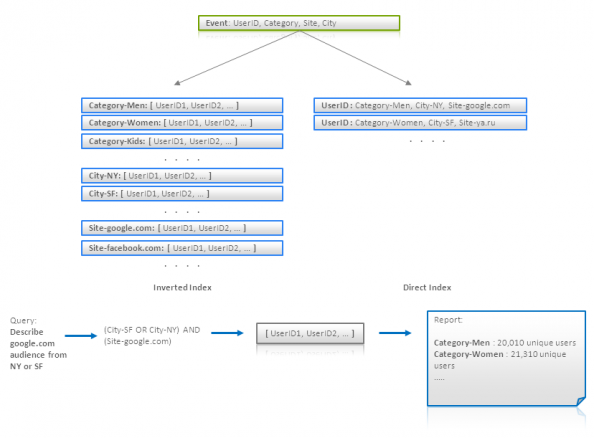
最后,我们需要明白,对每个UserID的随机查询是很没有效率的。我们可以通过批查询处理来解决这个问题。这意味着,对于一些用户集,我们可以进行预处理(不同的查询条件)。
适用性: Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库。
层级式模型 Hierarchy Modeling Techniques
(11) 树形聚合Tree Aggregation
树形或是任意的图(需反规格化)可以被直接打成一条记录或文档存放。
- 当树形结构被一次性取出时这会非常有效率(如:我们需要展示一个blog的树形评论)
- 搜索和任何存取这个实体都会存在问题。
- 对于大多数NoSQL的实现来说,更新数据都是很不经济的(相比起独立结点来说)
Tree Aggregation
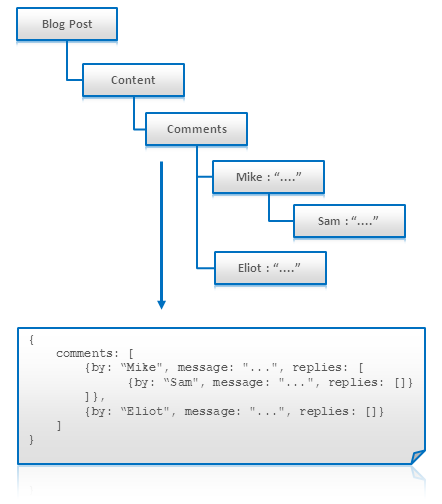
适用性: Key-Value 键值对数据库, Document Databases 文档数据库
(12) 邻接列表 Adjacency Lists
Adjacency Lists 邻接列表是一种图 – 每一个结点都是一个独立的记录,其包含了 所有的父结点或子结点。这样,我们就可以通过给定的父或子结点来进行搜索。当然,我们需要通过hop查询遍历图。这个技术在广度和深度查询,以及得到某个结点的子树上没有效率。
适用性: Key-Value 键值对数据库, Document Databases 文档数据库
(13) Materialized Paths
Materialized Paths 可以帮助避免递归遍历(如:树形结构)。这个技术也可以被认为是反规格化的一种变种。其想法是为每个结点加上父结点或子结点的标识属性,这样就可以不需要遍历就知道所有的后裔结点和祖先结点了:
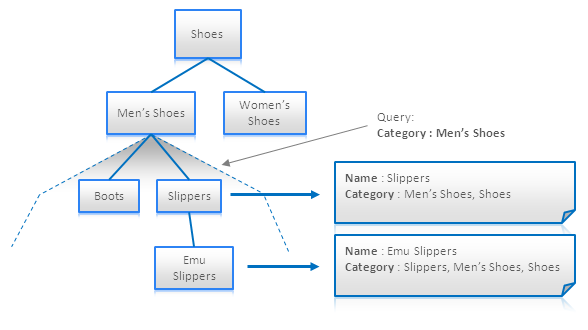
这个技术对于全文搜索引擎来说非常有帮助,因为其可以允许把一个层级结构转成一个文档。上面的示图中我们可以看到所有的商品或Men’s Shoes下的子分类可以被一条很短的查询语句处理——只需要给定个分类名。
Materialized Paths 可以存储一个ID的集合,或是一堆ID拼出的字符串。后者允许你通过一个正则表达式来搜索一个特定的分支路径。下图展示了这个技术(分支的路径包括了结点本身):

适用性: Key-Value 键值对数据库, Document Databases 文档数据, Search Engines 搜索引擎
(14) 嵌套集 Nested Sets
Nested sets 嵌套集是树形结构的标准技术。它被广泛地用在了关系性数据库中,它完全地适用于 Key-Value 键值对数据库 和 Document Databases 文档数据库。这个技术的想法是把叶子结点存储成一个数组,并通过使用索引的开始和结束来映射每一个非叶子结点到一个叶子结点集,就如下图所示一样:
这样的数据结构对于immutable data不变的数据 有非常不错的效率,因为其点内存空间小,并且可以很快地找出所有的叶子结点而不需要树的遍历。尽管如此,在插入和更新上需要很高的性能成本,因为新的叶子结点需要大规模地更新索引。
适用性: Key-Value Stores 键值数据库, Document Databases 文档数据库
(15) 嵌套文档扁平化:有限的字段名 Nested Documents Flattening: Numbered Field Names
搜索引擎基本上来说和扁平文档一同工作,如:每一个文档是一个扁平的字段和值的例表。这种数据模型的用来把业务实体映射到一个文本文档上,如果你的业务实体有很复杂的内部结构,这可能会变得很有挑战。一个典型的挑战是把一个有层级的文档映映射出来。例如,文档中嵌套另一个文档。让我们看看下面的示例:
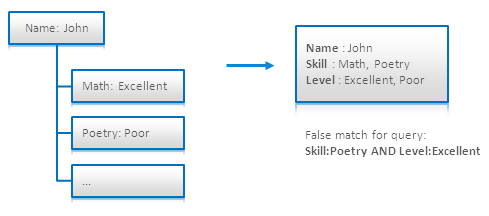
上面的每一个业务实体代码一种简历。其包括了人名和一个技能列表。我把这个层级文档映射成一个文本文档,一种方法是创建 Skill 和 Level 字段。这个模型可以通过技术或是等级来搜索一个人,而上图标注的那样的组合查询则会失败。(陈皓注:因为分不清Excellent是否是Math还是Poetry上的)
在引用中的 [4.6] 给出了一种解决方案。其为每个字段都标上数字 Skill_i 和 Level_i,这样就可以分开搜索每一个对(下图中使用了OR来遍历查找所有可能的字段):
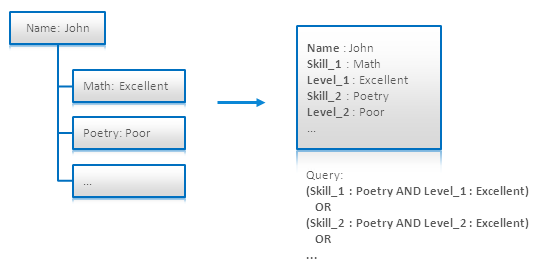
这样的方式根本没有扩展性,对于一些复杂的问题来说只会让代码复杂度和维护工作变大。
适用性: Search Engines 全文搜索
(16)嵌套文档扁平化:邻近查询 Nested Documents Flattening: Proximity Queries
在附录 [4.6]中给出了这个技术用来解决扁平层次文档。它用邻近的查询来限制可被查询的单词的范围。下图中,所有的技能和等级被放在一个字段中,叫 SkillAndLevel,查询中出现的 “Excellent” 和 “Poetry” 必需一个紧跟另一个:
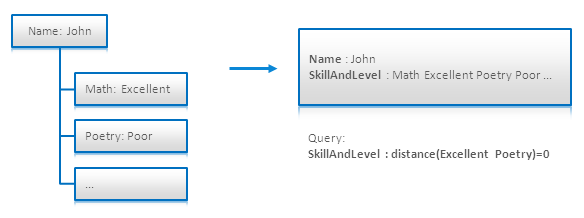
附录 [4.3] 中讲述了这个技术被用在Solr中的一个成功案例。
适用性: Search Engines 全文搜索
(17) 图结构批处理 Batch Graph Processing
Graph databases 图数据库,如 neo4j 是一个出众的图数据库,尤其是使用一个结点来探索邻居结点,或是探索两个或少量结点前的关系。但是处理大量的图数据是很没有效率的,因为图数据库的性能和扩展性并不是其目的。分布式的图数据处理可以被 MapReduce 和 Message Passing pattern 来处理。如: 在我前一篇的文章中的那个示例。这个方法可以让 Key-Value stores, Document databases, 和 BigTable-style databases 适合于处理大图。
Applicability: Key-Value Stores, Document Databases, BigTable-style Databases
参考
Finally, I provide a list of useful links related to NoSQL data modeling:
Key-Value Stores:
http://www.devshed.com/c/a/MySQL/Database-Design-Using-KeyValue-Tables/
- http://antirez.com/post/Sorting-in-key-value-data-model.html
- http://stackoverflow.com/questions/3554169/difference-between-document-based-and-key-value-based-databases
- http://dbmsmusings.blogspot.com/2010/03/distinguishing-two-major-types-of_29.html
BigTable-style Databases:
http://www.slideshare.net/ebenhewitt/cassandra-datamodel-4985524
- http://www.slideshare.net/mattdennis/cassandra-data-modeling
- http://nosql.mypopescu.com/post/17419074362/cassandra-data-modeling-examples-with-matthew-f-dennis
- http://s-expressions.com/2009/03/08/hbase-on-designing-schemas-for-column-oriented-data-stores/
- http://jimbojw.com/wiki/index.php?title=Understanding_Hbase_and_BigTable
Document Databases:
http://www.slideshare.net/mongodb/mongodb-schema-design-richard-kreuters-mongo-berlin-preso
- http://www.michaelhamrah.com/blog/2011/08/data-modeling-at-scale-mongodb-mongoid-callbacks-and-denormalizing-data-for-efficiency/
- http://seancribbs.com/tech/2009/09/28/modeling-a-tree-in-a-document-database/
- http://www.mongodb.org/display/DOCS/Schema+Design
- http://www.mongodb.org/display/DOCS/Trees+in+MongoDB
- http://blog.fiesta.cc/post/11319522700/walkthrough-mongodb-data-modeling
Full Text Search Engines:
http://www.searchworkings.org/blog/-/blogs/query-time-joining-in-lucene
- http://www.lucidimagination.com/devzone/technical-articles/solr-and-rdbms-basics-designing-your-application-best-both
- http://blog.griddynamics.com/2011/07/solr-experience-search-parent-child.html
- http://www.lucidimagination.com/blog/2009/07/18/the-spanquery/
- http://blog.mgm-tp.com/2011/03/non-standard-ways-of-using-lucene/
- http://www.slideshare.net/MarkHarwood/proposal-for-nested-document-support-in-lucene
- http://mysolr.com/tips/denormalized-data-structure/
- http://sujitpal.blogspot.com/2010/10/denormalizing-maps-with-lucene-payloads.html
- http://java.dzone.com/articles/hibernate-search-mapping-entit
Graph Databases:
http://docs.neo4j.org/chunked/stable/tutorial-comparing-models.html
- http://blog.neo4j.org/2010/03/modeling-categories-in-graph-database.html
- http://skillsmatter.com/podcast/nosql/graph-modelling
- http://www.umiacs.umd.edu/~jimmylin/publications/Lin_Schatz_MLG2010.pdf
Demensionality Reduction:
http://www.slideshare.net/mmalone/scaling-gis-data-in-nonrelational-data-stores
- http://blog.notdot.net/2009/11/Damn-Cool-Algorithms-Spatial-indexing-with-Quadtrees-and-Hilbert-Curves
- http://www.trisis.co.uk/blog/?p=1287
(全文完) (转载本站文章请注明作者和出处 酷壳 – CoolShell.cn ,请勿用于任何商业用途)
——=== 访问 酷壳404页面 寻找遗失儿童。 ===—— 74 分类: 数据库 标签: Database, NoSQL, SQL
(10 人打了分,平均分: 4.90 )
Loading ...
相关文章
- 2012年06月20日 -- 性能调优攻略
- 2009年12月01日 -- SQL的Where语句
- 2012年12月10日 -- 程序员疫苗:代码注入
- 2011年11月10日 -- 千万别用MongoDB?真的吗?!
- 2009年11月27日 -- MySQL性能优化的最佳20+条经验
- 2009年04月24日 -- MySQL: InnoDB 还是 MyISAM?
- 2010年12月31日 -- 6个有用的MySQL语句
- 2009年06月05日 -- 【原创】SQL栏目树的代码 Zemanta
评论 (41) Trackbacks (5) 发表评论 Trackback
Tesla
2012年5月15日09:08 | /#1
2012年5月15日09:09 | /#2
回复 | 引用 文章很长,先抢个沙发,呵呵。 现在我正在自学PHP和JS。书上的 都是一些很简单的小例子,根本不会 有什么业务上的项目,对这个有点迷惑
2012年5月15日09:34 | /#3
013231
2012年5月15日09:47 | /#4
wiizane
2012年5月15日10:43 | /#5
2012年5月15日12:22 | /#6
ciel
2012年5月15日11:31 | /#7
回复 | 引用 其实NoSQL只是SQL的re-approach吧.
bluishoul
2012年5月15日12:49 | /#8
回复 | 引用 http://highlyscalable.files.wordpress.com/2012/03/aggregates-joins.png?w=594 这个图看不到…
{kind=link}
2012年5月15日12:50 | /#9
2012年5月15日13:28 | /#10
回复 | 引用 看过redis的代码,觉得底层的数据结构真是实现的太底层了,差一点连malloc函数都换了。 Nosql特别适合做缓存,呵呵 好文,感谢博主~~~
火力fire
2012年5月15日20:47 | /#11
回复 | 引用 云计算会进一步刺激nosql的流行吗,mangodb之类的
2012年5月15日23:19 | /#12
回复 | 引用 感觉nosql就是一个带有安全保障的cache
2012年5月15日23:54 | /#13
回复 | 引用 额。。。楼主哪来这么多时间写这么长的文章呵~
YY
2012年5月16日14:43 | /#14
回复 | 引用 bluishoul :http://highlyscalable.files.wordpress.com/2012/03/aggregates-joins.png?w=594 这个图看不到…
(8) 键组合索引 Composite Key Index的配图…wordpress,显然被墙了
2012年5月16日16:21 | /#15
回复 | 引用 很给力.问下,sqlite是nosql的一种吗
2012年5月16日17:02 | /#16
回复 | 引用 刚开始以为是mysql。。。看来我最近接触mysql太多了,看花眼了
鸣
2012年5月16日19:36 | /#17
偶系老虎
2012年5月16日20:58 | /#18
回复 | 引用 完全没有大数据集合的使用经验和机会啊。。。真希望能参与这种工作。。。
2012年5月16日21:20 | /#19
阿德
2012年5月17日07:41 | /#20
2012年5月17日16:32 | /#21
lcl
2012年5月17日20:33 | /#22
2012年5月17日23:56 | /#23
zukhz
2012年5月18日09:15 | /#24
2012年5月18日11:41 | /#25
2012年5月19日14:27 | /#26
回复 | 引用 @learn linux sqlite是SQL数据库,不是NoSQL的。它是个轻量级的SQL数据库。
000
2012年5月19日14:59 | /#27
回复 | 引用 刚开始以为是mysql。。。看来我最近接触mysql太多了,看花眼了
2012年5月21日14:58 | /#28
回复 | 引用 完全没有大数据集合的使用经验和机会啊。。。真希望能参与这种工作。。。
coofucoo
2012年5月22日14:30 | /#29
回复 | 引用 翻译的确实值得提高,看到一半直接去看英文了。 NOSQL只适合做cache有点绝对了。如果说我们平日用不到NOSQL的话很可能是我们的应用还没有需要那么高的扩展性。什么需求用什么技术,倒不是说NOSQL就解决所有问题。 NOSQL建模技术中所透露的信息实际上绝大多数还是反规范化技术。一般在企业开发时这种反规范化技术都是在性能优化时用的。这种方式可以适合企业开发主要是因为两点: 1,企业开发数据量和规模都远远小于互联网应用。 2,企业应用增长速度也往往比较缓慢,可以有时间应对。 相反互联网应用在前两条上都不成立,所以设计互联网应用时更需要经验,必须在数据建模时就考虑性能做一些反规范化处理,从而不会在未来高速增长过程中出现问题。这就又给程序员们提出了新的挑战。
2012年5月22日16:10 | /#30
回复 | 引用 期待你也能写自己的博客。另,你后面说的那两点只能说明你对企业和互联网都还不是很懂,努力哦。
2012年5月23日15:51 | /#31
2012年5月27日09:21 | /#32
Sorra
2012年6月7日22:44 | /#33
回复 | 引用 哇,原来这篇被翻译出来了啊!我存的英文版看得有点费劲(有的逻辑连接词看不明白……) 太好了,感谢!
2012年6月13日10:04 | /#34
jialin
2012年6月28日09:10 | /#35
qqloving
2012年7月12日18:34 | /#36
labchy
2012年7月17日13:45 | /#37
qqloving
2012年7月17日16:31 | /#38
回复 | 引用 再看了一遍还是不是很懂。。。。。。。。。。。。。。。。。。
2012年10月17日13:32 | /#39
回复 | 引用 刚刚打算用mongodb。 过来先看看建模。
2013年3月29日16:37 | /#40
回复 | 引用 挺好的,最近打算入门mongodb.感觉不难
2013年7月19日14:53 | /#41
回复 | 引用 您文中有句话【但这样的SQL很没有效率,因为category数据太多了。】 我查看了下原文【cannot be handled efficiently using an inverted index if the number of categories is big.】 在没看原文之前,我以为的意思是【SELECT count(distinct(user_id)) … GROUP BY category】这个SQL由于每个category对应的UserID值太多,造成效率差。但这里应该是指的Inverted Index的方式,不会因为UserID值太多而影响性能。 实在理解不了,后来瞄了下原文,发现对应的意思是如果category的数量多,会造成每个category都需要进行一次计算(合并)才能统计出报表 原文这句话好像没有说上面的SQL性能差,而是针对【inverted index】说的。
- 2012年5月21日01:01 | /#1
- 2012年5月25日22:55 | /#2
NoSQL 数据建模技术 | _yiihsia[互联网后端技术]
- 2012年8月4日10:45 | /#3
- 2012年12月31日22:27 | /#4
转载:NoSQL 数据建模技术 | Yuan Peng`s Tech Blog
- 2013年8月11日12:48 | /#5
NoSQLDataModelingTechniques – 数据库 – 开发者 昵称 (必填)
电子邮箱 (我们会为您保密) (必填) 网址
rsync 的核心算法 用Unix的设计思想来应对多变的需求
本站公告
访问 酷壳404页面 寻找遗失儿童!
酷壳建议大家多使用RSS访问阅读(本站已经是全文输出,推荐使用cloud.feedly.com 或 digg.com)。有相关事宜欢迎电邮:haoel(at)hotmail.com。最后,感谢大家对酷壳的支持和体谅!
最新文章
- 数据即代码:元驱动编程
- 数据的游戏:冰与火
- 7个示例科普CPU Cache
- 加班与效率
- 类型的本质和函数式实现
- C语言全局变量那些事儿
- 二叉树迭代器算法
- Alan Cox:大教堂、市集与市议会
- IoC/DIP其实是一种管理思想
- Alan Cox:单向链表中prev指针的妙用
- Javascript 装载和执行
- 无锁HashMap的原理与实现
- 浏览器的渲染原理简介
- 疫苗:Java HashMap的死循环
- “C++的数组不支持多态”?
- Unix考古记:一个“遗失”的shell
- PFIF网上寻人协议
- “作环保的程序员,从不用百度开始”
- 《Rework》摘录及感想
- 实例分析Java Class的文件结构
- 并发框架Disruptor译文
- sed 简明教程
- AWK 简明教程
- Linus:利用二级指针删除单向链表
- 从面向对象的设计模式看软件设计
- 应该知道的Linux技巧
- 程序算法与人生选择
- Web工程师的工具箱
- 如此理解面向对象编程
- 程序员疫苗:代码注入
全站热门
- 程序员技术练级攻略
- 简明 Vim 练级攻略
- 如何学好C语言
- 6个变态的C语言Hello World程序
- 由12306.cn谈谈网站性能技术
- 应该知道的Linux技巧
- “21天教你学会C++”
- Android将允许纯C/C++开发应用
- 我是怎么招聘程序员的
- 做个环保主义的程序员
- “作环保的程序员,从不用百度开始”
- 28个Unix/Linux的命令行神器
- C++ 程序员自信心曲线图
- 编程真难啊
- Web开发中需要了解的东西
- SteveY对Amazon和Google平台的吐槽
- 20本最好的Linux免费书籍
- 如何写出无法维护的代码
- 程序算法与人生选择
- 各种流行的编程风格
- Windows编程革命简史
- 如何学好C++语言
- 深入理解C语言
- 面试题:火车运煤问题
- 三个事和三个问题
- 别的程序员是怎么读你的简历的
- 老手是这样教新手编程的
- C语言的谜题
- 偷了世界的程序员
- 再谈“我是怎么招聘程序员的”(上)
新浪微博
标签
agile AJAX Algorithm Android Bash C++ Coding CSS Database Design design pattern ebook Flash Game Go Google HTML IE Java Javascript jQuery Linux MySQL OOP password Performance PHP Programmer programming language Puzzle Python Ruby SQL TDD UI Unix vim Web Windows XML 口令 安全 程序员 算法 面试
分类目录
- .NET编程 (2)
- Ajax开发 (9)
- C/C++语言 (54)
- Erlang (1)
- Java语言 (29)
- PHP脚本 (11)
- Python (21)
- Ruby (5)
- Unix/Linux (66)
- Web开发 (99)
- Windows (12)
- 业界新闻 (25)
- 企业应用 (2)
- 技术新闻 (32)
- 技术管理 (10)
- 技术读物 (115)
- 操作系统 (43)
- 数据库 (10)
- 杂项资源 (251)
- 流程方法 (43)
- 程序设计 (70)
- 系统架构 (7)
- 编程工具 (61)
- 编程语言 (160)
- 网络安全 (22)
- 职场生涯 (32)
- 趣味问题 (13)
- 轶事趣闻 (145)
归档
- 2013年八月 (1)
- 2013年七月 (8)
- 2013年六月 (2)
- 2013年五月 (3)
- 2013年四月 (3)
- 2013年三月 (3)
- 2013年二月 (5)
- 2013年一月 (1)
- 2012年十二月 (4)
- 2012年十一月 (5)
- 2012年十月 (3)
- 2012年九月 (4)
- 2012年八月 (8)
- 2012年七月 (4)
- 2012年六月 (7)
- 2012年五月 (6)
- 2012年四月 (6)
- 2012年三月 (6)
- 2012年二月 (3)
- 2012年一月 (6)
- 2011年十二月 (5)
- 2011年十一月 (9)
- 2011年十月 (6)
- 2011年九月 (5)
- 2011年八月 (14)
- 2011年七月 (6)
- 2011年六月 (12)
- 2011年五月 (5)
- 2011年四月 (18)
- 2011年三月 (16)
- 2011年二月 (16)
- 2011年一月 (18)
- 2010年十二月 (11)
- 2010年十一月 (11)
- 2010年十月 (19)
- 2010年九月 (15)
- 2010年八月 (10)
- 2010年七月 (20)
- 2010年六月 (9)
- 2010年五月 (13)
- 2010年四月 (12)
- 2010年三月 (11)
- 2010年二月 (7)
- 2010年一月 (9)
- 2009年十二月 (22)
- 2009年十一月 (27)
- 2009年十月 (17)
- 2009年九月 (15)
- 2009年八月 (21)
- 2009年七月 (18)
- 2009年六月 (19)
- 2009年五月 (27)
- 2009年四月 (53)
2009年三月 (43)
最新评论
deanzhang1984: 照此说脚本语言里的脚本基本上都只是配置而已,后面都有个解释器 在解释执行。
- rookiepig: 当然,长期看皓哥文章,技术部分还是没话说。 学习了不少~
- Jacob: 当你研究某一领域深入,或者技术见长,或者感觉到时间不够用的时 候你就会明白百度为什么成为众矢之的了。@二陶
- blog: Webmaster, I am the admin at . We profile SEO Plugins for WordPress blogs for on-site and off-site SEO....
- ligand: 我觉得,学习C++与学习其他语言,如Python、Java有 一个非常大的不同之处,就是学习C++时人们不自觉得就会去探究 其下一层的实现机制。而学Python,一般都不会去关心...
- ligand: 楼主这篇还是很中立、客观的。观之有收获。
- yaplog: Hello there, I discovered your site by way of Google while searching for a similar matter, your web site came...
- YYX: 唉,别绕弯子 直接来本质的。就是编译器 连接器 的工作原理,与语言本身毫无关系
- Willie Maranville: A formidable share, I simply given this onto a colleague who was doing a bit evaluation on this....
- Anonymous: 什么“元驱动编程”,无非就是那句话:配置文件复杂到一定程度就 变成了一门语言。这不就是脚本语言的由来么。不是什么新概念,干 嘛要搞得神神叨叨…
- Isabel Zomberg: I�m impressed, I must say. Actually rarely do I encounter a weblog that�s each educative and...
- code4craft: JS那个例子的特定程度跟其他几个完全不一样嘛。 话说回来,这种配置式的写法,属于”写完之前不知道 它到底该是什么样子”,写好了读起来可能比较...
- YU_YU: boost的命令行解析库呢? 语言设计就是库设计,一门语言是否好用,就是库是否好用,仅此而 已
- henix: 任何一个业务程序只要足够复杂,到最后都会发展成一个解释器(i nterpret)。对这点深有体会。文章的例子还是比较清楚的 ,个人感觉 json / lua 比 S 表达式易读。
- jimshao: 这里一个提法忽视了一个问题域的本质问题,解耦到底是目的还是手 段?我很赞同解耦的重要性,但是我认为强调解耦并不能帮助看官们 如何解决问题,一定会问我怎么才能解耦,如何解耦才是合适...
友情链接
- 陈皓的博客
- 并发编程
- 四火的唠叨
- devtext 开发者社区
- Claymore's blog
- Dutor.net
- bones7456
- Keengle's Blog
- 简明现代魔法
- 罗素工作室
- 代码回音
- HelloGcc Working Group
- 吕毅的Blog
- Todd Wei的Blog
- C++爱好者博客
- HTML5研究小组
- 12Free
- 朱文昊Albert Zhu
- C瓜哥的博客
- 开源吧
- 靖难|魔都小码农
- ACMer
- 陈鹏个人博客
- OneCoder
- 狂Shell – Happy Hacking
- TekTea's Blog
-
功能
- 登录
- 文章RSS
- 评论RSS
- WordPress.org
版权所有 © 2009-2013 酷壳 – CoolShell.cn
主题由 NeoEase 提供, 通过 XHTML 1.1 和 CSS 3 验证.
检测到你还在使用百度这个搜索引擎, 做为一个程序员,这是一种自暴自弃!