影响Java EE性能的十大问题
Posted on影响Java EE性能的十大问题
本文作者是一名有10多年经验的高级系统架构师,他的主要专业领域是Java EE、中间件和JVM技术。他在性能优化和提升方面也有很深刻的见解,下面他将和大家分享一下常见的10个影响Java EE性能问题。
1.缺乏正确的容量规划
容量规划是一个全面的和发展的过程标准,预测当前和未来的IT环境容量需求。制定合理的容量规划不仅会确保和跟踪当前IT生产能力和稳定性,同时也会确保新项目以最小的风险部署到现有的生产环境中。硬件、中间件、JVM、调整等在项目部署之前就应该准备好。
2.Java EE中间件环境规范不足
“没有规矩,不成方圆”。第二个比较普遍的原因是Java EE中间件或者基础架构不规范。在项目初始,新平台上面没有制定合理的规范,导致系统稳定性差。这会增加客户成本,所以花时间去制定合理的Java EE中间件环境规范是必须的。这项工作应与初始容量规划迭代相结合。

3.Java虚拟机垃圾回收过度
各位对“java.lang.OutOfMemoryError”这个错误信息是不是很熟悉呢?由于JVM的内存空间过度消耗(Java堆、本机堆等)而抛出的异常。
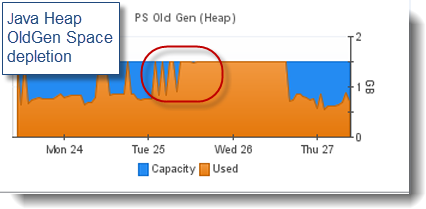
垃圾收集问题并不一定会表现为一个OOM条件,过度的垃圾收集可以理解成是JVM GC线程在短时间里进行轻微或超量收集集合数据而导致的JVM暂停时间很长和性能下降。可能有以下几个原因:
1、与JVM的负载量和应用程序内存占用量相比,Java堆可能选择的太小。
2、JVM GC策略使用不合理。
3、应用程序静态或动态内存占用量太大,不适合在32位JVM上使用。
4、JVM OldGen随着时间推移,泄漏越来越严重,而GC在几个小时或者几天后才发现。
5、JVM PermGen空间(只有HotSpot VM)或本机堆随着时间推移会泄露是一个非常普遍的问题;OOM的错误往往是观察一段时间后,应用程序进行动态调动。
6、YoungGen和OldGen的比例空间与你的应用程序不匹配。
7、Java堆在32位的VM上太大,导致本机堆溢出,具体可以表现为OOM试着去链接一个新的Java EE应用程序、创建一个新的Java线程或者需要计算本地内存分配任务。
建议:
1、观察和深入理解JVM垃圾回收。启动GC,根据健康合理的评估来提供所有的数据。
2、记住,GC方面的相关问题不会在开发中或者功能测试时发现,它需要在多用户高负载的测试环境下发现。
4.与外部系统集成过多或过少
导致Java EE性能差的第四个原因是高分布式系统,典型案例是电信IT环境。在这个环境中,一个中间件领域(例如,服务总线)很少会做所有的工作,而仅仅是把一些业务“委托”给其他部分,例如产品质量,客户资料和订单管理,到其他Java EE中间件平台或遗留系统中,如支持各种不同的负载类型和通信协议的大型机。
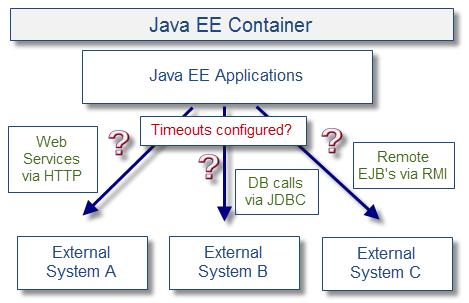
这样的外部系统调用意味着客户端的Java EE应用程序触发创建或重用套接字链接从外部系统中读写数据。根据业务流程的实施和实现可以配置成同步调用或异步调用。需要注意的是,响应时间会根据外部系统的稳定状况进行改变,所以通过适当的使用超时来保护Java EE应用程序和中间件也是非常重要的。
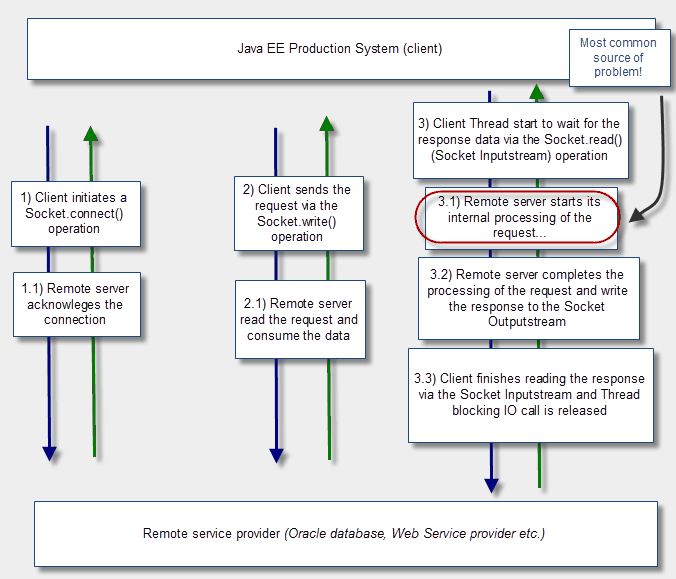
下面这3种情况是经常出现问题和性能降低的地方:
1、同步和相继调用太多的外部系统。
2、在Java EE客户端应用程序和外部系统之间链接超时,使数据丢失或者值太高导致客户端线程被卡住,从而导致多米拉效应。
3、超时,但程序仍正常执行,可是中间件不处理这种奇怪的路径。
最后,建议多进行负面测试,这意味着需要“人为”创造产生这些问题的条件,用来测试应用程序和中间件之间是如何处理外部系统错误。
5.缺乏适当的数据库SQL调优和容量规划
大家可能会对这一个感到惊奇:数据库问题。大多数Java EE企业系统是依赖关系型数据库处理复杂的业务流程。一个基础扎实稳固的数据库环境可以确保IT环境有规模的增长,来支持日益不断扩大的业务。
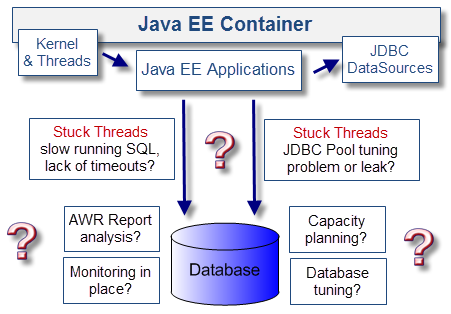
在实际中,与数据库相关的性能问题是很常见的。由于多数数据库事务处理都是由JDBC数据源执行的(包括关系持久化API,例如Hibernate)。而性能问题最初都会表现为线程阻塞。
以下是我在10年的工作中,经常出现的关于数据库方面的问题(以Oracle数据库为例):
1、孤立的,长时间运行的SQL。主要表现为线程阻塞、SQL没有进行优化、缺少索引、非最佳的执行计划、返回大量数据集等等。
2、表或行级数据锁定。当提交一个双阶段事务模型时(例如,臭名昭著的Oracle可疑事务)。Java EE容器可能会留下一些未处理的事务等待最后的提交或回滚,留下的数据锁能触发性能问题,直到最后的锁被移除。例如中间件断电或者服务器崩溃都可能引起这些情况发生。
3、缺乏合理规范的数据库管理工具。例如Oracle里面的REDO logs,数据库数据文件等。磁盘空间不足,日志文件不旋转等都会触发较大的性能问题和断电情况。
建议:
1、合理的容量规划,包括负载和性能测试都是必不可少的,优化数据环境和及时发现问题。
2、如果是使用Oracle数据库,确保DBA团队定期审查AWR报告,尤其是在上下关联的事件和根源分析过程中。
3、使用JVM线程存储和AWR报告查明SQL运行缓慢的原因或者使用监控工具来做。
4、加强“操作”方面的数据库环境(磁盘空间、数据文件、重做日志、表空间等)以适当的监视和报警。如果不这么做,会让客户端IT环境出现较多的断电情况和花许多时间进行故障调修。
6.特定应用程序性能问题
下面关注的是比较严重的Java EE应用程序问题。关于特定应用程序性能问题,总结了以下几个点:
1、线程安全的代码问题
2、通信API缺少超时设置
3、I/O、JDBC或者关系型API资源管理问题
4、缺乏适当的数据缓存
5、数据缓存过度
6、过多的日志记录
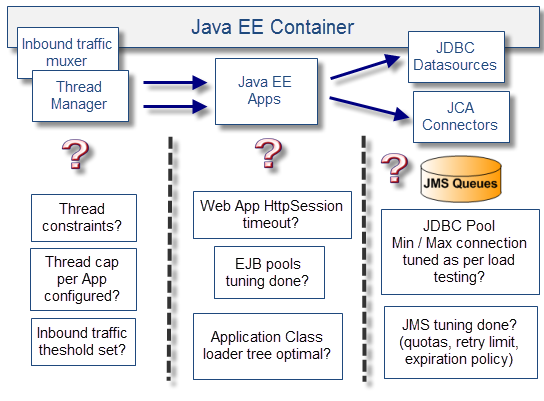
7.Java EE中间件调优问题
一般Java EE中间件都已经够用了,只是缺少必要的优化。大多数Java EE容器都能有多种方案供你的应用程序和业务进程选择。
如果没有进行适当的调整和实践,那么Java EE容器可能会处于一种消极的状态。
下图是视图和检查列表示例:
8.主动监控不足
缺乏监控,并不会带来实际性能问题,但它会影响你对Java EE平台性能和健康状况的了解。最终,这个环境可以达到一个破发点,这可能会暴露出一些缺陷和问题(JVM的内存泄漏,等等)。
以我的经验来看,如果一开始不进行监控,而是运行几个月或者几年后再进行,平台稳定性将大打折扣。
也就是说,改善现有的环境永远都不会晚。下面是一些建议:
1、复查现有Java EE环境监测能力和找到需改进的地方。
2、监测方案应该尽可能的覆盖整个环境。
3、监控方案应该符合容量规划进程。
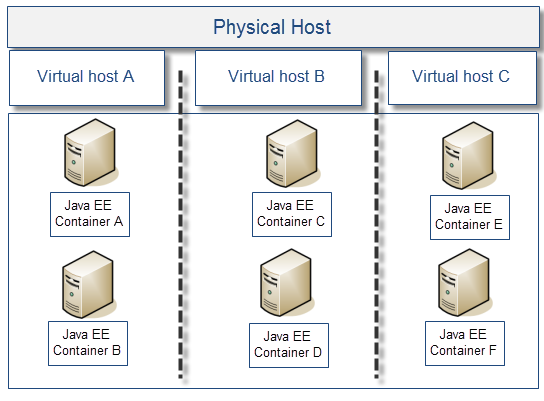
9.公共基础设施硬件饱和
这个问题经常在有太多的Java EE中间件环境随着JVM进程被部署到现有硬件上面时看到。太多的JVM进程对有限的物理CPU核心来说是一个真正的程序性能杀手。另外,随着客户端业务的增长,硬件方面也需要再次考虑。
10.网络延迟
最后一个影响性能问题的是网络,网络问题时不时的都会发生,如路由器、交换机和DNS服务器失败。更常见的是在一个高度分散的IT环境中定期或间歇性延迟。下面图片中的例子是一个位于同一区域的Weblogic集群通信与Oracle数据库服务器之间的延迟。
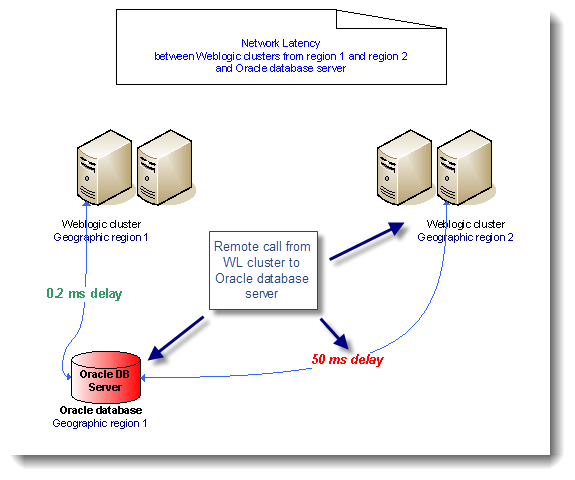
间歇或定期的延迟会触发一些重要的性能问题,以不同的方式影响Java EE应用程序。
1、因为大量的fetch迭代(网络传入和传出),涉及大数据集的数据查询问题的应用会非常受网络延迟的影响
2、应用程序在处理外部系统大数据负载(例如XML数据)时也会很受网络延迟的影响,会在发送和接收响应时产生巨大的响应间隔。
3、Java EE容器复制过程(集群)也会受到影响,并且会让故障转移功能(如多播或单播数据包损失)处于风险中。
JDBC行数据“预取”、XML数据压缩和数据缓存可以减少网络延迟。在设计一个新的网络拓扑时,应该仔细检查这种网络延迟问题。
希望本文能够帮助您理解一些常见的性能问题和压力点,每个IT环境都是独一无二的,所以文中提到的问题不一定会是您遇到的,您可以把您遇到的问题拿出来和大家一起分享一下!
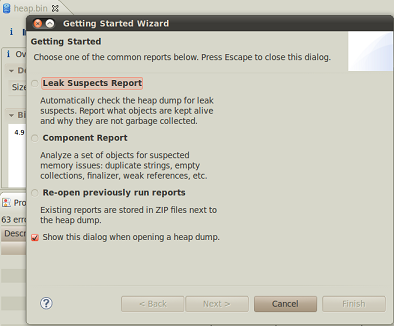
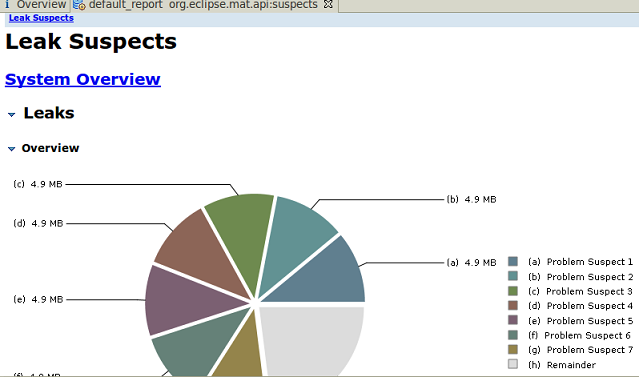
 第二步:分析堆文件
第二步:分析堆文件
 第三步:查看html
第三步:查看html

 (2)从根集能引用到的对象
(2)从根集能引用到的对象
 (3)显示平台包括的所有类的实例数量
(3)显示平台包括的所有类的实例数量
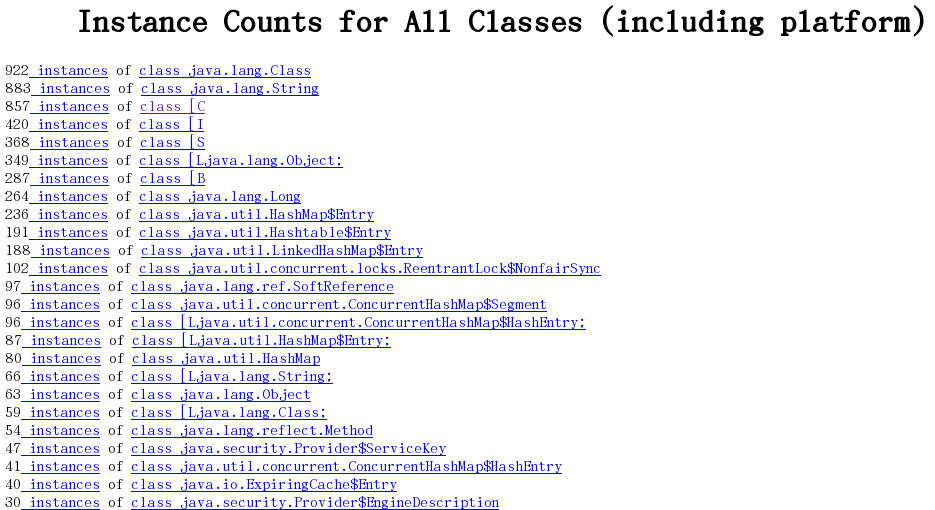 (4)堆实例的分布表
(4)堆实例的分布表

 更多关于对象查询语言的信息,见这篇文章:
更多关于对象查询语言的信息,见这篇文章:
{kind=link}