Introduction to Structured Query Language(ZQL)
Introduction to Structured Query Language
Version 3.31
This page is a tutorial of the Structured Query Language(also known as SQL) and is a pioneering effort on the World Wide Web, as this is the first comprehensive SQL tutorial available on the Internet. SQL allows users to access data in relational database management systems, such as Oracle, Sybase, Informix, Microsoft SQL Server, Access, and others, by allowing users to describe the data the user wishes to see. SQL also allows users to define the data in a database, and manipulate that data. This page will describe how to use SQL, and give examples. The SQL used in this document is "ANSI", or standard SQL, and no SQL features of specific database management systems will be discussed until the "Nonstandard SQL" section. It is recommended that you print this page, so that you can easily refer back to previous examples.
Table of Contents
Basics of the SELECT Statement
Conditional Selection
Relational Operators
Compound Conditions
IN & BETWEEN
Using LIKE
Joins
Keys
Performing a Join
Eliminating Duplicates
Aliases & In/Subqueries
Aggregate Functions
Views
Creating New Tables
Altering Tables
Adding Data
Deleting Data
Updating Data
Indexes
GROUP BY & HAVING
More Subqueries
EXISTS & ALL
UNION & Outer Joins
Embedded SQL
Common SQL Questions
Nonstandard SQL
Syntax Summary
Important Links
Basics of the SELECT Statement
In a relational database, data is stored in tables. An example table would relate Social Security Number, Name, and Address:
EmployeeAddressTable SSN FirstName LastName Address City State 512687458 Joe Smith 83 First Street Howard Ohio 758420012 Mary Scott 842 Vine Ave. Losantiville Ohio 102254896 Sam Jones 33 Elm St. Paris New York 876512563 Sarah Ackerman 440 U.S. 110 Upton Michigan
Now, let's say you want to see the address of each employee. Use the SELECT statement, like so:
SELECT FirstName, LastName, Address, City, State
FROM EmployeeAddressTable;
The following is the results of your query of the database:
First Name Last Name Address City State Joe Smith 83 First Street Howard Ohio Mary Scott 842 Vine Ave. Losantiville Ohio Sam Jones 33 Elm St. Paris New York Sarah Ackerman 440 U.S. 110 Upton Michigan
To explain what you just did, you asked for the all of data in the EmployeeAddressTable, and specifically, you asked for the columns called FirstName, LastName, Address, City, and State. Note that column names and table names do not have spaces...they must be typed as one word; and that the statement ends with a semicolon (;). The general form for a SELECT statement, retrieving all of the rows in the table is:
SELECT ColumnName, ColumnName, ...
FROM TableName;
To get all columns of a table without typing all column names, use:
SELECT /* FROM TableName;
Each database management system (DBMS) and database software has different methods for logging in to the database and entering SQL commands; see the local computer "guru" to help you get onto the system, so that you can use SQL.
Conditional Selection
To further discuss the SELECT statement, let's look at a new example table (for hypothetical purposes only):
EmployeeStatisticsTable EmployeeIDNo Salary Benefits Position 010 75000 15000 Manager 105 65000 15000 Manager 152 60000 15000 Manager 215 60000 12500 Manager 244 50000 12000 Staff 300 45000 10000 Staff 335 40000 10000 Staff 400 32000 7500 Entry-Level 441 28000 7500 Entry-Level
Relational Operators
There are six Relational Operators in SQL, and after introducing them, we'll see how they're used:
= Equal <> or != (see manual) Not Equal < Less Than > Greater Than <= Less Than or Equal To >= Greater Than or Equal To
The WHEREclause is used to specify that only certain rows of the table are displayed, based on the criteria described in that WHERE clause. It is most easily understood by looking at a couple of examples.
If you wanted to see the EMPLOYEEIDNO's of those making at or over $50,000, use the following:
SELECT EMPLOYEEIDNO
FROM EMPLOYEESTATISTICSTABLE
WHERE SALARY >= 50000;
Notice that the >= (greater than or equal to) sign is used, as we wanted to see those who made greater than $50,000, or equal to $50,000, listed together. This displays:
EMPLOYEEIDNO
010
105
152
215
244
The WHERE description, SALARY >= 50000, is known as a condition. The same can be done for text columns:
SELECT EMPLOYEEIDNO
FROM EMPLOYEESTATISTICSTABLE
WHERE POSITION = 'Manager';
This displays the ID Numbers of all Managers. Generally, with text columns, stick to equal to or not equal to, and make sure that any text that appears in the statement is surrounded by single quotes (').
More Complex Conditions: Compound Conditions
The AND operator joins two or more conditions, and displays a row only if that row's data satisfies ALL conditions listed (i.e. all conditions hold true). For example, to display all staff making over $40,000, use:
SELECT EMPLOYEEIDNO
FROM EMPLOYEESTATISTICSTABLE
WHERE SALARY > 40000 AND POSITION = 'Staff';
The OR operator joins two or more conditions, but returns a row if ANY of the conditions listed hold true. To see all those who make less than $40,000 or have less than $10,000 in benefits, listed together, use the following query:
SELECT EMPLOYEEIDNO
FROM EMPLOYEESTATISTICSTABLE
WHERE SALARY < 40000 OR BENEFITS < 10000;
AND & OR can be combined, for example:
SELECT EMPLOYEEIDNO
FROM EMPLOYEESTATISTICSTABLE
WHERE POSITION = 'Manager' AND SALARY > 60000 OR BENEFITS > 12000;
First, SQL finds the rows where the salary is greater than $60,000 and the position column is equal to Manager, then taking this new list of rows, SQL then sees if any of these rows satisfies the previous AND condition or the condition that the Benefits column is greater then $12,000. Subsequently, SQL only displays this second new list of rows, keeping in mind that anyone with Benefits over $12,000 will be included as the OR operator includes a row if either resulting condition is True. Also note that the AND operation is done first.
To generalize this process, SQL performs the AND operation(s) to determine the rows where the AND operation(s) hold true (remember: all of the conditions are true), then these results are used to compare with the OR conditions, and only display those remaining rows where the conditions joined by the OR operator hold true.
To perform OR's before AND's, like if you wanted to see a list of employees making a large salary (>$50,000) or have a large benefit package (>$10,000), and that happen to be a manager, use parentheses:
SELECT EMPLOYEEIDNO
FROM EMPLOYEESTATISTICSTABLE
WHERE POSITION = 'Manager' AND (SALARY > 50000 OR BENEFIT > 10000);
IN & BETWEEN
An easier method of using compound conditions uses IN or BETWEEN. For example, if you wanted to list all managers and staff:
SELECT EMPLOYEEIDNO
FROM EMPLOYEESTATISTICSTABLE
WHERE POSITION IN ('Manager', 'Staff');
or to list those making greater than or equal to $30,000, but less than or equal to $50,000, use:
SELECT EMPLOYEEIDNO
FROM EMPLOYEESTATISTICSTABLE
WHERE SALARY BETWEEN 30000 AND 50000;
To list everyone not in this range, try:
SELECT EMPLOYEEIDNO
FROM EMPLOYEESTATISTICSTABLE
WHERE SALARY NOT BETWEEN 30000 AND 50000;
Similarly, NOT IN lists all rows excluded from the IN list.
UsingLIKE
Look at the EmployeeStatisticsTable, and say you wanted to see all people whose last names started with "L"; try:
SELECT EMPLOYEEIDNO
FROM EMPLOYEEADDRESSTABLE
WHERE LASTNAME LIKE 'L%';
The percent sign (%) is used to represent any possible character (number, letter, or punctuation) or set of characters that might appear after the "L". To find those people with LastName's ending in "L", use '%L', or if you wanted the "L" in the middle of the word, try '%L%'. The '%' can be used for any characters, in that relative position to the given characters. NOT LIKE displays rows not fitting the given description. Other possiblities of using LIKE, or any of these discussed conditionals, are available, though it depends on what DBMS you are using; as usual, consult a manual or your system manager or administrator for the available features on your system, or just to make sure that what you are trying to do is available and allowed. This disclaimer holds for the features of SQL that will be discussed below. This section is just to give you an idea of the possibilities of queries that can be written in SQL.
Joins
In this section, we will only discuss inner joins, and equijoins, as in general, they are the most useful. For more information, try the SQL links at the bottom of the page.
Good database design suggests that each table lists data only about a single entity, and detailed information can be obtained in a relational database, by using additional tables, and by using a join.
First, take a look at these example tables:
AntiqueOwners
OwnerID OwnerLastName OwnerFirstName 01 Jones Bill 02 Smith Bob 15 Lawson Patricia 21 Akins Jane 50 Fowler Sam
Orders
OwnerID ItemDesired 02 Table 02 Desk 21 Chair 15 Mirror
Antiques
SellerID BuyerID Item 01 50 Bed 02 15 Table 15 02 Chair 21 50 Mirror 50 01 Desk 01 21 Cabinet 02 21 Coffee Table 15 50 Chair 01 15 Jewelry Box 02 21 Pottery 21 02 Bookcase 50 01 Plant Stand
Keys
First, let's discuss the concept of keys. A primary key is a column or set of columns that uniquely identifies the rest of the data in any given row. For example, in the AntiqueOwners table, the OwnerID column uniquely identifies that row. This means two things: no two rows can have the same OwnerID, and, even if two owners have the same first and last names, the OwnerID column ensures that the two owners will not be confused with each other, because the unique OwnerID column will be used throughout the database to track the owners, rather than the names.
Aforeign key is a column in a table where that column is a primary key of another table, which means that any data in a foreign key column must have corresponding data in the other table where that column is the primary key. In DBMS-speak, this correspondence is known as referential integrity. For example, in the Antiques table, both the BuyerID and SellerID are foreign keys to the primary key of the AntiqueOwners table (OwnerID; for purposes of argument, one has to be an Antique Owner before one can buy or sell any items), as, in both tables, the ID rows are used to identify the owners or buyers and sellers, and that the OwnerID is the primary key of the AntiqueOwners table. In other words, all of this "ID" data is used to refer to the owners, buyers, or sellers of antiques, themselves, without having to use the actual names.
Performing a Join
The purpose of these keys is so that data can be related across tables, without having to repeat data in every table--this is the power of relational databases. For example, you can find the names of those who bought a chair without having to list the full name of the buyer in the Antiques table...you can get the name by relating those who bought a chair with the names in the AntiqueOwners table through the use of the OwnerID, which relates the data in the two tables. To find the names of those who bought a chair, use the following query:
SELECT OWNERLASTNAME, OWNERFIRSTNAME
FROM ANTIQUEOWNERS, ANTIQUES
WHERE BUYERID = OWNERID AND ITEM = 'Chair';
Note the following about this query...notice that both tables involved in the relation are listed in the FROM clause of the statement. In the WHERE clause, first notice that the ITEM = 'Chair' part restricts the listing to those who have bought (and in this example, thereby owns) a chair. Secondly, notice how the ID columns are related from one table to the next by use of the BUYERID = OWNERID clause. Only where ID's match across tables and the item purchased is a chair (because of the AND), will the names from the AntiqueOwners table be listed. Because the joining condition used an equal sign, this join is called an equijoin. The result of this query is two names: Smith, Bob & Fowler, Sam.
Dot notation refers to prefixing the table names to column names, to avoid ambiguity, as such:
SELECT ANTIQUEOWNERS.OWNERLASTNAME, ANTIQUEOWNERS.OWNERFIRSTNAME
FROM ANTIQUEOWNERS, ANTIQUES
WHERE ANTIQUES.BUYERID = ANTIQUEOWNERS.OWNERID AND ANTIQUES.ITEM = 'Chair';
As the column names are different in each table, however, this wasn't necessary.
DISTINCT and Eliminating Duplicates
Let's say that you want to list the ID and names of only those people who have sold an antique. Obviously, you want a list where each seller is only listed once--you don't want to know how many antiques a person sold, just the fact that this person sold one (for counts, see the Aggregate Function section below). This means that you will need to tell SQL to eliminate duplicate sales rows, and just list each person only once. To do this, use the DISTINCT keyword.
First, we will need an equijoin to the AntiqueOwners table to get the detail data of the person's LastName and FirstName. However, keep in mind that since the SellerID column in the Antiques table is a foreign key to the AntiqueOwners table, a seller will only be listed if there is a row in the AntiqueOwners table listing the ID and names. We also want to eliminate multiple occurences of the SellerID in our listing, so we use DISTINCTon the column where the repeats may occur.
To throw in one more twist, we will also want the list alphabetized by LastName, then by FirstName (on a LastName tie), then by OwnerID (on a LastName and FirstName tie). Thus, we will use the ORDER BY clause:
SELECT DISTINCT SELLERID, OWNERLASTNAME, OWNERFIRSTNAME
FROM ANTIQUES, ANTIQUEOWNERS
WHERE SELLERID = OWNERID
ORDER BY OWNERLASTNAME, OWNERFIRSTNAME, OWNERID;
In this example, since everyone has sold an item, we will get a listing of all of the owners, in alphabetical order by last name. For future reference (and in case anyone asks), this type of join is considered to be in the category of inner joins.
Aliases & In/Subqueries
In this section, we will talk about Aliases, In and the use of subqueries, and how these can be used in a 3-table example. First, look at this query which prints the last name of those owners who have placed an order and what the order is, only listing those orders which can be filled (that is, there is a buyer who owns that ordered item):
SELECT OWN.OWNERLASTNAME Last Name, ORD.ITEMDESIRED Item Ordered
FROM ORDERS ORD, ANTIQUEOWNERS OWN
WHERE ORD.OWNERID = OWN.OWNERID
AND ORD.ITEMDESIRED IN
(SELECT ITEM
FROM ANTIQUES);
This gives:
Last Name Item Ordered
Smith Table
Smith Desk
Akins Chair
Lawson Mirror
There are several things to note about this query:
- First, the "Last Name" and "Item Ordered" in the Select lines gives the headers on the report.
- The OWN & ORD are aliases; these are new names for the two tables listed in the FROM clause that are used as prefixes for all dot notations of column names in the query (see above). This eliminates ambiguity, especially in the equijoin WHERE clause where both tables have the column named OwnerID, and the dot notation tells SQL that we are talking about two different OwnerID's from the two different tables.
- Note that the Orders table is listed first in the FROM clause; this makes sure listing is done off of that table, and the AntiqueOwners table is only used for the detail information (Last Name).
- Most importantly, the AND in the WHERE clause forces the In Subquery to be invoked ("= ANY" or "= SOME" are two equivalent uses of IN). What this does is, the subquery is performed, returning all of the Items owned from the Antiques table, as there is no WHERE clause. Then, for a row from the Orders table to be listed, the ItemDesired must be in that returned list of Items owned from the Antiques table, thus listing an item only if the order can be filled from another owner. You can think of it this way: the subquery returns a set of Items from which each ItemDesired in the Orders table is compared; the In condition is true only if the ItemDesired is in that returned set from the Antiques table.
- Also notice, that in this case, that there happened to be an antique available for each one desired...obviously, that won't always be the case. In addition, notice that when the IN, "= ANY", or "= SOME" is used, that these keywords refer to any possible row matches, not column matches...that is, you cannot put multiple columns in the subquery Select clause, in an attempt to match the column in the outer Where clause to one of multiple possible column values in the subquery; only one column can be listed in the subquery, and the possible match comes from multiple row values in that one column, not vice-versa.
Whew! That's enough on the topic of complex SELECT queries for now. Now on to other SQL statements.
Miscellaneous SQL Statements
Aggregate Functions
I will discuss five important aggregate functions: SUM, AVG, MAX, MIN, and COUNT. They are called aggregate functions because they summarize the results of a query, rather than listing all of the rows.
- SUM () gives the total of all the rows, satisfying any conditions, of the given column, where the given column is numeric.
- AVG () gives the average of the given column.
- MAX () gives the largest figure in the given column.
- MIN () gives the smallest figure in the given column.
- COUNT(/*) gives the number of rows satisfying the conditions.
Looking at the tables at the top of the document, let's look at three examples:
SELECT SUM(SALARY), AVG(SALARY)
FROM EMPLOYEESTATISTICSTABLE;
This query shows the total of all salaries in the table, and the average salary of all of the entries in the table.
SELECT MIN(BENEFITS)
FROM EMPLOYEESTATISTICSTABLE
WHERE POSITION = 'Manager';
This query gives the smallest figure of the Benefits column, of the employees who are Managers, which is 12500.
SELECT COUNT(/*)
FROM EMPLOYEESTATISTICSTABLE
WHERE POSITION = 'Staff';
This query tells you how many employees have Staff status (3).
Views
In SQL, you might (check your DBA) have access to create views for yourself. What a view does is to allow you to assign the results of a query to a new, personal table, that you can use in other queries, where this new table is given the view name in your FROM clause. When you access a view, the query that is defined in your view creation statement is performed (generally), and the results of that query look just like another table in the query that you wrote invoking the view. For example, to create a view:
CREATE VIEW ANTVIEW AS SELECT ITEMDESIRED FROM ORDERS;
Now, write a query using this view as a table, where the table is just a listing of all Items Desired from the Orders table:
SELECT SELLERID
FROM ANTIQUES, ANTVIEW
WHERE ITEMDESIRED = ITEM;
This query shows all SellerID's from the Antiques table where the Item in that table happens to appear in the Antview view, which is just all of the Items Desired in the Orders table. The listing is generated by going through the Antique Items one-by-one until there's a match with the Antview view. Views can be used to restrict database access, as well as, in this case, simplify a complex query.
Creating New Tables
All tables within a database must be created at some point in time...let's see how we would create the Orders table:
CREATE TABLE ORDERS
(OWNERID INTEGER NOT NULL,
ITEMDESIRED CHAR(40) NOT NULL);
This statement gives the table name and tells the DBMS about each column in the table. Please note that this statement uses generic data types, and that the data types might be different, depending on what DBMS you are using. As usual, check local listings. Some common generic data types are:
- Char(x) - A column of characters, where x is a number designating the maximum number of characters allowed (maximum length) in the column.
- Integer - A column of whole numbers, positive or negative.
- Decimal(x, y) - A column of decimal numbers, where x is the maximum length in digits of the decimal numbers in this column, and y is the maximum number of digits allowed after the decimal point. The maximum (4,2) number would be 99.99.
- Date - A date column in a DBMS-specific format.
- Logical - A column that can hold only two values: TRUE or FALSE.
One other note, the NOT NULL means that the column must have a value in each row. If NULL was used, that column may be left empty in a given row.
Altering Tables
Let's add a column to the Antiques table to allow the entry of the price of a given Item:
ALTER TABLE ANTIQUES ADD (PRICE DECIMAL(8,2) NULL);
The data for this new column can be updated or inserted as shown later.
Adding Data
To insert rows into a table, do the following:
INSERT INTO ANTIQUES VALUES (21, 01, 'Ottoman', 200.00);
This inserts the data into the table, as a new row, column-by-column, in the pre-defined order. Instead, let's change the order and leave Price blank:
INSERT INTO ANTIQUES (BUYERID, SELLERID, ITEM)
VALUES (01, 21, 'Ottoman');
Deleting Data
Let's delete this new row back out of the database:
DELETE FROM ANTIQUES
WHERE ITEM = 'Ottoman';
But if there is another row that contains 'Ottoman', that row will be deleted also. Let's delete all rows (one, in this case) that contain the specific data we added before:
DELETE FROM ANTIQUES
WHERE ITEM = 'Ottoman' AND BUYERID = 01 AND SELLERID = 21;
Updating Data
Let's update a Price into a row that doesn't have a price listed yet:
UPDATE ANTIQUES SET PRICE = 500.00 WHERE ITEM = 'Chair';
This sets all Chair's Prices to 500.00. As shown above, more WHERE conditionals, using AND, must be used to limit the updating to more specific rows. Also, additional columns may be set by separating equal statements with commas.
Miscellaneous Topics
Indexes
Indexes allow a DBMS to access data quicker (please note: this feature is nonstandard/not available on all systems). The system creates this internal data structure (the index) which causes selection of rows, when the selection is based on indexed columns, to occur faster. This index tells the DBMS where a certain row is in the table given an indexed-column value, much like a book index tells you what page a given word appears. Let's create an index for the OwnerID in the AntiqueOwners column:
CREATE INDEX OID_IDX ON ANTIQUEOWNERS (OWNERID);
Now on the names:
CREATE INDEX NAME_IDX ON ANTIQUEOWNERS (OWNERLASTNAME, OWNERFIRSTNAME);
To get rid of an index, drop it:
DROP INDEX OID_IDX;
By the way, you can also "drop" a table, as well (careful!--that means that your table is deleted). In the second example, the index is kept on the two columns, aggregated together--strange behavior might occur in this situation...check the manual before performing such an operation.
Some DBMS's do not enforce primary keys; in other words, the uniqueness of a column is not enforced automatically. What that means is, if, for example, I tried to insert another row into the AntiqueOwners table with an OwnerID of 02, some systems will allow me to do that, even though, we do not, as that column is supposed to be unique to that table (every row value is supposed to be different). One way to get around that is to create a unique index on the column that we want to be a primary key, to force the system to enforce prohibition of duplicates:
CREATE UNIQUE INDEX OID_IDX ON ANTIQUEOWNERS (OWNERID);
GROUP BY & HAVING
One special use of GROUP BY is to associate an aggregate function (especially COUNT; counting the number of rows in each group) with groups of rows. First, assume that the Antiques table has the Price column, and each row has a value for that column. We want to see the price of the most expensive item bought by each owner. We have to tell SQL to group each owner's purchases, and tell us the maximum purchase price:
SELECT BUYERID, MAX(PRICE)
FROM ANTIQUES
GROUP BY BUYERID;
Now, say we only want to see the maximum purchase price if the purchase is over $1000, so we use the HAVING clause:
SELECT BUYERID, MAX(PRICE)
FROM ANTIQUES
GROUP BY BUYERID
HAVING PRICE > 1000;
More Subqueries
Another common usage of subqueries involves the use of operators to allow a Where condition to include the Select output of a subquery. First, list the buyers who purchased an expensive item (the Price of the item is $100 greater than the average price of all items purchased):
SELECT OWNERID
FROM ANTIQUES
WHERE PRICE >
(SELECT AVG(PRICE) + 100
FROM ANTIQUES);
The subquery calculates the average Price, plus $100, and using that figure, an OwnerID is printed for every item costing over that figure. One could use DISTINCT OWNERID, to eliminate duplicates.
List the Last Names of those in the AntiqueOwners table, ONLY if they have bought an item:
SELECT OWNERLASTNAME
FROM ANTIQUEOWNERS
WHERE OWNERID =
(SELECT DISTINCT BUYERID
FROM ANTIQUES);
The subquery returns a list of buyers, and the Last Name is printed for an Antique Owner if and only if the Owner's ID appears in the subquery list (sometimes called a candidate list).
For an Update example, we know that the gentleman who bought the bookcase has the wrong First Name in the database...it should be John:
UPDATE ANTIQUEOWNERS
SET OWNERFIRSTNAME = 'John'
WHERE OWNERID =
(SELECT BUYERID
FROM ANTIQUES
WHERE ITEM = 'Bookcase');
First, the subquery finds the BuyerID for the person(s) who bought the Bookcase, then the outer query updates his First Name.
Remember this rule about subqueries: when you have a subquery as part of a WHERE condition, the Select clause in the subquery must have columns that match in number and type to those in the Where clause of the outer query. In other words, if you have "WHERE ColumnName = (SELECT...);", the Select must have only one column in it, to match the ColumnName in the outer Where clause, and they must match in type (both being integers, both being character strings, etc.).
EXISTS & ALL
EXISTS uses a subquery as a condition, where the condition is True if the subquery returns any rows, and False if the subquery does not return any rows; this is a nonintuitive feature with few unique uses. However, if a prospective customer wanted to see the list of Owners only if the shop dealt in Chairs, try:
SELECT OWNERFIRSTNAME, OWNERLASTNAME
FROM ANTIQUEOWNERS
WHERE EXISTS
(SELECT /*
FROM ANTIQUES
WHERE ITEM = 'Chair');
If there are any Chairs in the Antiques column, the subquery would return a row or rows, making the EXISTS clause true, causing SQL to list the Antique Owners. If there had been no Chairs, no rows would have been returned by the outside query.
ALL is another unusual feature, as ALL queries can usually be done with different, and possibly simpler methods; let's take a look at an example query:
SELECT BUYERID, ITEM
FROM ANTIQUES
WHERE PRICE >= ALL
(SELECT PRICE
FROM ANTIQUES);
This will return the largest priced item (or more than one item if there is a tie), and its buyer. The subquery returns a list of all Prices in the Antiques table, and the outer query goes through each row of the Antiques table, and if its Price is greater than or equal to every (or ALL) Prices in the list, it is listed, giving the highest priced Item. The reason ">=" must be used is that the highest priced item will be equal to the highest price on the list, because this Item is in the Price list.
UNION & Outer Joins
There are occasions where you might want to see the results of multiple queries together, combining their output; use UNION. To merge the output of the following two queries, displaying the ID's of all Buyers, plus all those who have an Order placed:
SELECT BUYERID
FROM ANTIQUEOWNERS
UNION
SELECT OWNERID
FROM ORDERS;
Notice that SQL requires that the Select list (of columns) must match, column-by-column, in data type. In this case BuyerID and OwnerID are of the same data type (integer). Also notice that SQL does automatic duplicate elimination when using UNION (as if they were two "sets"); in single queries, you have to use DISTINCT.
The outer join is used when a join query is "united" with the rows not included in the join, and are especially useful if constant text "flags" are included. First, look at the query:
SELECT OWNERID, 'is in both Orders & Antiques'
FROM ORDERS, ANTIQUES
WHERE OWNERID = BUYERID
UNION
SELECT BUYERID, 'is in Antiques only'
FROM ANTIQUES
WHERE BUYERID NOT IN
(SELECT OWNERID
FROM ORDERS);
The first query does a join to list any owners who are in both tables, and putting a tag line after the ID repeating the quote. The UNION merges this list with the next list. The second list is generated by first listing those ID's not in the Orders table, thus generating a list of ID's excluded from the join query. Then, each row in the Antiques table is scanned, and if the BuyerID is not in this exclusion list, it is listed with its quoted tag. There might be an easier way to make this list, but it's difficult to generate the informational quoted strings of text.
This concept is useful in situations where a primary key is related to a foreign key, but the foreign key value for some primary keys is NULL. For example, in one table, the primary key is a salesperson, and in another table is customers, with their salesperson listed in the same row. However, if a salesperson has no customers, that person's name won't appear in the customer table. The outer join is used if the listing of all salespersons is to be printed, listed with their customers, whether the salesperson has a customer or not--that is, no customer is printed (a logical NULL value) if the salesperson has no customers, but is in the salespersons table. Otherwise, the salesperson will be listed with each customer.
ENOUGH QUERIES!!! you say?...now on to something completely different...
Embedded SQL--an ugly example (do not write a program like this...for purposes of argument ONLY)
// -To get right to it, here is an example program that uses Embedded
SQL. Embedded SQL allows programmers to connect to a database and
include SQL code right in the program, so that their programs can
use, manipulate, and process data from a database.
-This example C Program (using Embedded SQL) will print a report.
-This program will have to be precompiled for the SQL statements,
before regular compilation.
-The EXEC SQL parts are the same (standard), but the surrounding C
code will need to be changed, including the host variable
declarations, if you are using a different language.
-Embedded SQL changes from system to system, so, once again, check
local documentation, especially variable declarations and logging
in procedures, in which network, DBMS, and operating system
considerations are crucial. //
//////////////////////////////////////////////////
// THIS PROGRAM IS NOT COMPILABLE OR EXECUTABLE //
// IT IS FOR EXAMPLE PURPOSES ONLY //
//////////////////////////////////////////////////
/#include
// This section declares the host variables; these will be the
variables your program uses, but also the variable SQL will put
values in or take values out. //
EXEC SQL BEGIN DECLARE SECTION;
int BuyerID;
char FirstName[100], LastName[100], Item[100];
EXEC SQL END DECLARE SECTION;
// This includes the SQLCA variable, so that some error checking can be done. //
EXEC SQL INCLUDE SQLCA;
main() {
// This is a possible way to log into the database //
EXEC SQL CONNECT UserID/Password;
// This code either says that you are connected or checks if an error
code was generated, meaning log in was incorrect or not possible. // if(sqlca.sqlcode) {
printf(Printer, "Error connecting to database server.\n");
exit();
}
printf("Connected to database server.\n");
// This declares a "Cursor". This is used when a query returns more
than one row, and an operation is to be performed on each row
resulting from the query. With each row established by this query,
I'm going to use it in the report. Later, "Fetch" will be used to
pick off each row, one at a time, but for the query to actually
be executed, the "Open" statement is used. The "Declare" just
establishes the query. //
EXEC SQL DECLARE ItemCursor CURSOR FOR
SELECT ITEM, BUYERID
FROM ANTIQUES
ORDER BY ITEM;
EXEC SQL OPEN ItemCursor;
// +-- You may wish to put a similar error checking block here --+ //
// Fetch puts the values of the "next" row of the query in the host
variables, respectively. However, a "priming fetch" (programming
technique) must first be done. When the cursor is out of data, a
sqlcode will be generated allowing us to leave the loop. Notice
that, for simplicity's sake, the loop will leave on any sqlcode,
even if it is an error code. Otherwise, specific code checking must
be performed. //
EXEC SQL FETCH ItemCursor INTO :Item, :BuyerID;
while(!sqlca.sqlcode) {
// With each row, we will also do a couple of things. First, bump the
price up by $5 (dealer's fee) and get the buyer's name to put in
the report. To do this, I'll use an Update and a Select, before
printing the line on the screen. The update assumes however, that
a given buyer has only bought one of any given item, or else the
price will be increased too many times. Otherwise, a "RowID" logic
would have to be used (see documentation). Also notice the colon before host variable names when used inside of SQL statements. //
EXEC SQL UPDATE ANTIQUES
SET PRICE = PRICE + 5
WHERE ITEM = :Item AND BUYERID = :BuyerID;
EXEC SQL SELECT OWNERFIRSTNAME, OWNERLASTNAME
INTO :FirstName, :LastName
FROM ANTIQUEOWNERS
WHERE BUYERID = :BuyerID;
printf("%25s %25s %25s", FirstName, LastName, Item);
// Ugly report--for example purposes only! Get the next row. //
EXEC SQL FETCH ItemCursor INTO :Item, :BuyerID;
}
// Close the cursor, commit the changes (see below), and exit the
program. //
EXEC SQL CLOSE DataCursor;
EXEC SQL COMMIT RELEASE;
exit();
}
Common SQL Questions--Advanced Topics (see FAQ link for several more)
- Why can't I just ask for the first three rows in a table? --Because in relational databases, rows are inserted in no particular order, that is, the system inserts them in an arbitrary order; so, you can only request rows using valid SQL features, like ORDER BY, etc.
- What is this DDL and DML I hear about? --DDL (Data Definition Language) refers to (in SQL) the Create Table statement...DML (Data Manipulation Language) refers to the Select, Update, Insert, and Delete statements.
- Aren't database tables just files? --Well, DBMS's store data in files declared by system managers before new tables are created (on large systems), but the system stores the data in a special format, and may spread data from one table over several files. In the database world, a set of files created for a database is called a tablespace. In general, on small systems, everything about a database (definitions and all table data) is kept in one file.
- (Related question) Aren't database tables just like spreadsheets? --No, for two reasons. First, spreadsheets can have data in a cell, but a cell is more than just a row-column-intersection. Depending on your spreadsheet software, a cell might also contain formulas and formatting, which database tables cannot have (currently). Secondly, spreadsheet cells are often dependent on the data in other cells. In databases, "cells" are independent, except that columns are logically related (hopefully; together a row of columns describe an entity), and, other than primary key and foreign key constraints, each row in a table in independent from one another.
- How do I import a text file of data into a database? --Well, you can't do it directly...you must use a utility, such as Oracle's SQL/*Loader, or write a program to load the data into the database. A program to do this would simply go through each record of a text file, break it up into columns, and do an Insert into the database.
- What is a schema? --A schema is a logical set of tables, such as the Antiques database above...usually, it is thought of as simply "the database", but a database can hold more than one schema. For example, a star schema is a set of tables where one large, central table holds all of the important information, and is linked, via foreign keys, to dimension tables which hold detail information, and can be used in a join to create detailed reports.
- What are some general tips you would give to make my SQL queries and databases better and faster (optimized)?
- You should try, if you can, to avoid expressions in Selects, such as SELECT ColumnA + ColumnB, etc. The query optimizer of the database, the portion of the DBMS that determines the best way to get the required data out of the database itself, handles expressions in such a way that would normally require more time to retrieve the data than if columns were normally selected, and the expression itself handled programmatically.
- Minimize the number of columns included in a Group By clause.
- If you are using a join, try to have the columns joined on (from both tables) indexed.
- When in doubt, index.
Unless doing multiple counts or a complex query, use COUNT(/*) (the number of rows generated by the query) rather than COUNT(Column_Name).
What is normalization? --Normalization is a technique of database design that suggests that certain criteria be used when constructing a table layout (deciding what columns each table will have, and creating the key structure), where the idea is to eliminate redundancy of non-key data across tables. Normalization is usually referred to in terms of forms, and I will introduce only the first three, even though it is somewhat common to use other, more advanced forms (fourth, fifth, Boyce-Codd; see documentation).
First Normal Form refers to moving data into separate tables where the data in each table is of a similar type, and by giving each table a primary key.
Putting data in Second Normal Form involves taking out data off to other tables that is only dependent of a part of the key. For example, if I had left the names of the Antique Owners in the items table, that would not be in second normal form because that data would be redundant; the name would be repeated for each item owned, so the names were placed in their own table. The names themselves don't have anything to do with the items, only the identities of the buyers and sellers.
Third Normal Form involves getting rid of anything in the tables that doesn't depend solely on the primary key. Only include information that is dependent on the key, and move off data to other tables that are independent of the primary key, and create a primary keys for the new tables.
There is some redundancy to each form, and if data is in 3NF(shorthand for 3rd normal form), it is already in 1NFand 2NF. In terms of data design then, arrange data so that any non-primary key columns are dependent only on the whole primary key. If you take a look at the sample database, you will see that the way then to navigate through the database is through joins using common key columns.
Two other important points in database design are using good, consistent, logical, full-word names for the tables and columns, and the use of full words in the database itself. On the last point, my database is lacking, as I use numeric codes for identification. It is usually best, if possible, to come up with keys that are, by themselves, self-explanatory; for example, a better key would be the first four letters of the last name and first initial of the owner, like JONEB for Bill Jones (or for tiebreaking purposes, add numbers to the end to differentiate two or more people with similar names, so you could try JONEB1, JONEB2, etc.).
- What is the difference between a single-row query and a multiple-row query and why is it important to know the difference? --First, to cover the obvious, a single-row query is a query that returns one row as its result, and a multiple-row query is a query that returns more than one row as its result. Whether a query returns one row or more than one row is entirely dependent on the design (or schema) of the tables of the database. As query-writer, you must be aware of the schema, be sure to include enough conditions, and structure your SQL statement properly, so that you will get the desired result (either one row or multiple rows). For example, if you wanted to be sure that a query of the AntiqueOwners table returned only one row, consider an equal condition of the primary key-column, OwnerID.
Three reasons immediately come to mind as to why this is important. First, getting multiple rows when you were expecting only one, or vice-versa, may mean that the query is erroneous, that the database is incomplete, or simply, you learned something new about your data. Second, if you are using an update or delete statement, you had better be sure that the statement that you write performs the operation on the desired row (or rows)...or else, you might be deleting or updating more rows than you intend. Third, any queries written in Embedded SQL must be carefully thought out as to the number of rows returned. If you write a single-row query, only one SQL statement may need to be performed to complete the programming logic required. If your query, on the other hand, returns multiple rows, you will have to use the Fetch statement, and quite probably, some sort of looping structure in your program will be required to iterate processing on each returned row of the query.
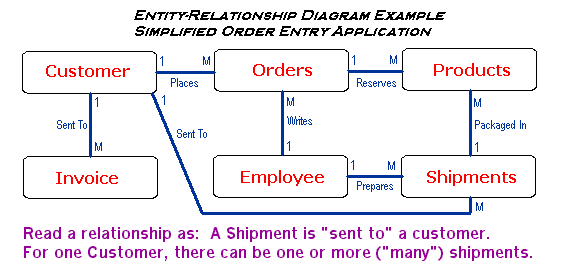
- What are relationships? --Another design question...the term "relationships" (often termed "relation") usually refers to the relationships among primary and foreign keys between tables. This concept is important because when the tables of a relational database are designed, these relationships must be defined because they determine which columns are or are not primary or foreign keys. You may have heard of an Entity-Relationship Diagram, which is a graphical view of tables in a database schema, with lines connecting related columns across tables. See the sample diagram at the end of this section or some of the sites below in regard to this topic, as there are many different ways of drawing E-R diagrams. But first, let's look at each kind of relationship...
A One-to-one relationship means that you have a primary key column that is related to a foreign key column, and that for every primary key value, there is one foreign key value. For example, in the first example, the EmployeeAddressTable, we add an EmployeeIDNo column. Then, the EmployeeAddressTable is related to the EmployeeStatisticsTable (second example table) by means of that EmployeeIDNo. Specifically, each employee in the EmployeeAddressTable has statistics (one row of data) in the EmployeeStatisticsTable. Even though this is a contrived example, this is a "1-1" relationship. Also notice the "has" in bold...when expressing a relationship, it is important to describe the relationship with a verb.
The other two kinds of relationships may or may not use logical primary key and foreign key constraints...it is strictly a call of the designer. The first of these is the one-to-many relationship ("1-M"). This means that for every column value in one table, there is one or more related values in another table. Key constraints may be added to the design, or possibly just the use of some sort of identifier column may be used to establish the relationship. An example would be that for every OwnerID in the AntiqueOwners table, there are one or more (zero is permissible too) Items bought in the Antiques table (verb: buy).
Finally, the many-to-many relationship ("M-M") does not involve keys generally, and usually involves idenifying columns. The unusual occurence of a "M-M" means that one column in one table is related to another column in another table, and for every value of one of these two columns, there are one or more related values in the corresponding column in the other table (and vice-versa), or more a common possibility, two tables have a 1-M relationship to each other (two relationships, one 1-M going each way). A [bad] example of the more common situation would be if you had a job assignment database, where one table held one row for each employee and a job assignment, and another table held one row for each job with one of the assigned employees. Here, you would have multiple rows for each employee in the first table, one for each job assignment, and multiple rows for each job in the second table, one for each employee assigned to the project. These tables have a M-M: each employee in the first table has many job assignments from the second table, and each job has many employees assigned to it from the first table. This is the tip of the iceberg on this topic...see the links below for more information and see the diagram below for a simplified example of an E-R diagram.
- What are some important nonstandard SQL features (extremely common question)? --Well, see the next section...
Nonstandard SQL..."check local listings"
- INTERSECT and MINUS are like the UNION statement, except that INTERSECT produces rows that appear in both queries, and MINUS produces rows that result from the first query, but not the second.
- Report Generation Features: the COMPUTE clause is placed at the end of a query to place the result of an aggregate function at the end of a listing, like COMPUTE SUM (PRICE); Another option is to use break logic: define a break to divide the query results into groups based on a column, like BREAK ON BUYERID. Then, to produce a result after the listing of a group, use COMPUTE SUM OF PRICE ON BUYERID. If, for example, you used all three of these clauses (BREAK first, COMPUTE on break second, COMPUTE overall sum third), you would get a report that grouped items by their BuyerID, listing the sum of Prices after each group of a BuyerID's items, then, after all groups are listed, the sum of all Prices is listed, all with SQL-generated headers and lines.
- In addition to the above listed aggregate functions, some DBMS's allow more functions to be used in Select lists, except that these functions (some character functions allow multiple-row results) are to be used with an individual value (not groups), on single-row queries.The functions are to be used only on appropriate data types, also. Here are some Mathematical Functions:
ABS(X) Absolute value-converts negative numbers to positive, or leaves positive numbers alone CEIL(X) X is a decimal value that will be rounded up. FLOOR(X) X is a decimal value that will be rounded down. GREATEST(X,Y) Returns the largest of the two values. LEAST(X,Y) Returns the smallest of the two values. MOD(X,Y) Returns the remainder of X / Y. POWER(X,Y) Returns X to the power of Y. ROUND(X,Y) Rounds X to Y decimal places. If Y is omitted, X is rounded to the nearest integer. SIGN(X) Returns a minus if X < 0, else a plus. SQRT(X) Returns the square root of X. Character Functions
LEFT(,X) Returns the leftmost X characters of the string. RIGHT(,X) Returns the rightmost X characters of the string. UPPER() Converts the string to all uppercase letters. LOWER() Converts the string to all lowercase letters. INITCAP() Converts the string to initial caps. LENGTH() Returns the number of characters in the string. || Combines the two strings of text into one, concatenated string, where the first string is immediately followed by the second. LPAD(,X,'/*') Pads the string on the left with the / (or whatever character is inside the quotes), to make the string X characters long. **RPAD(,X,'/') Pads the string on the right with the /* (or whatever character is inside the quotes), to make the string X characters long. SUBSTR(,X,Y) Extracts Y letters from the string beginning at position X. NVL(,)** The Null value function will substitute for any NULLs for in the . If the current value of is not NULL, NVL has no effect.
Syntax Summary--For Advanced Users Only
Here are the general forms of the statements discussed in this tutorial, plus some extra important ones (explanations given). REMEMBER that all of these statements may or may not be available on your system, so check documentation regarding availability:
ALTER TABLE
ADD|DROP|MODIFY (COLUMN SPECIFICATION[S]...see Create Table); --allows you to add or delete a column or columns from a table, or change the specification (data type, etc.) on an existing column; this statement is also used to change the physical specifications of a table (how a table is stored, etc.), but these definitions are DBMS-specific, so read the documentation. Also, these physical specifications are used with the Create Table statement, when a table is first created. In addition, only one option can be performed per Alter Table statement--either add, drop, ORmodify in a single statement.
COMMIT; --makes changes made to some database systems permanent (since the last COMMIT; known as a transaction)
CREATE [UNIQUE] INDEX
ON (); --UNIQUE is optional; within brackets.
CREATE TABLE
( [()] ,
...other columns); (also valid with ALTER TABLE)
--where SIZE is only used on certain data types (see above), and constraints include the following possibilities (automatically enforced by the DBMS; failure causes an error to be generated):
- NULL or NOT NULL (see above)
- UNIQUE enforces that no two rows will have the same value for this column
- PRIMARY KEY tells the database that this column is the primary key column (only used if the key is a one column key, otherwise a PRIMARY KEY (column, column, ...) statement appears after the last column definition.
- CHECK allows a condition to be checked for when data in that column is updated or inserted; for example, CHECK (PRICE > 0) causes the system to check that the Price column is greater than zero before accepting the value...sometimes implemented as the CONSTRAINT statement.
- DEFAULT inserts the default value into the database if a row is inserted without that column's data being inserted; for example, BENEFITS INTEGER DEFAULT = 10000
- FOREIGN KEY works the same as Primary Key, but is followed by: REFERENCES
(), which refers to the referential primary key.
CREATE VIEW
AS ;
DELETE FROM
WHERE ;
INSERT INTO
[()]
VALUES ();
ROLLBACK; --Takes back any changes to the database that you have made, back to the last time you gave a Commit command...beware! Some software uses automatic committing on systems that use the transaction features, so the Rollback command may not work.
SELECT [DISTINCT|ALL]
FROM
[WHERE ]
[GROUP BY ]
[HAVING ]
[ORDER BY [ASC|DESC]]; --where ASC|DESC allows the ordering to be done in ASCending or DESCending order
UPDATE
SET =
[WHERE ]; --if the Where clause is left out, all rows will be updated according to the Set statement
Important Links
Computing & SQL/DB Links: Netscape -- Oracle -- Sybase -- Informix --Microsoft
SQL Reference Page -- Ask the SQL Pro -- SQL Pro's Relational DB Useful Sites
Programmer's Source -- DBMS Sites -- inquiry.com -- DB Ingredients
Web Authoring -- Computing Dictionary -- DBMS Lab/Links -- SQL FAQ -- SQL Databases
RIT Database Design Page -- Database Jump Site -- Programming Tutorials on the Web
Development Resources -- Query List -- IMAGE SQL
Miscellaneous: CNN -- USA Today -- Pathfinder -- ZDNet -- Metroscope -- CNet
Internet Resource List -- Netcast Weather -- TechWeb -- LookSmart
Search Engines: Yahoo -- Alta Vista -- Excite -- WebCrawler -- Lycos -- Infoseek -- search.com
These sites are not endorsed by the author.
Disclaimer
I hope you have learned something from this introductory look at a very important language that is becoming more prevalent in the world of client-server computing. I wrote this web page in order to contribute something of value to the web and the web community. In fact, I have been informed that this document is being used at several colleges for use in database classes and for use by researchers. Also, look for this page in Waite Publishing's newest book about Borland C++ Builder, which will be out this summer, and in an upcoming Sams Publishing release. In addition, I would like to thank all of the people from across five continents who have contacted me regarding this web page.
I also hope to continue to add more material to this tutorial, such as topics about database design and nonstandard SQL extensions, even though I wish to stay away from material about individual Database Management Systems. Good luck in your SQL and other computing adventures.
Jim Hoffman
Comments or suggestions? Mail me at jhoffman@one.net.
Or you may wish to look at Jim Hoffman's Web Pages for more information about myself.
Copyright 1996-1997, James Hoffman. This document can be used for free by any Internet user, but cannot be included in another document, published in any other form, or mass produced in any way.
This page is best viewed with Netscape Navigator; it doesn't look quite right with Microsoft Internet Explorer.
Last updated: 8-25-1997; added some material.
http://w3.one.net/~jhoffman/sqltut.htm
来源: [http://zql.sourceforge.net/sqltut.html](http://zql.sourceforge.net/sqltut.html)
Java深度历险(六)——Java注解
在开发Java程序,尤其是Java EE应用的时候,总是免不了与各种配置文件打交道。以Java EE中典型的S(pring)S(truts)H(ibernate)架构来说,Spring、Struts和Hibernate这三个框架都有自己的XML格式的配置文件。这些配置文件需要与Java源代码保存同步,否则的话就可能出现错误。而且这些错误有可能到了运行时刻才被发现。把同一份信息保存在两个地方,总是个坏的主意。理想的情况是在一个地方维护这些信息就好了。其它部分所需的信息则通过自动的方式来生成。JDK 5中引入了源代码中的注解(annotation)这一机制。注解使得Java源代码中不但可以包含功能性的实现代码,还可以添加元数据。注解的功能类似于代码中的注释,所不同的是注解不是提供代码功能的说明,而是实现程序功能的重要组成部分。Java注解已经在很多框架中得到了广泛的使用,用来简化程序中的配置。
使用注解
在一般的Java开发中,最常接触到的可能就是@Override和@SupressWarnings这两个注解了。使用@Override的时候只需要一个简单的声明即可。这种称为标记注解(marker annotation ),它的出现就代表了某种配置语义。而其它的注解是可以有自己的配置参数的。配置参数以名值对的方式出现。使用 @SupressWarnings的时候需要类似@SupressWarnings({"uncheck", "unused"})这样的语法。在括号里面的是该注解可供配置的值。由于这个注解只有一个配置参数,该参数的名称默认为value,并且可以省略。而花括号则表示是数组类型。在JPA中的@Table注解使用类似@Table(name = "Customer", schema = "APP")这样的语法。从这里可以看到名值对的用法。在使用注解时候的配置参数的值必须是编译时刻的常量。
从某种角度来说,可以把注解看成是一个XML元素,该元素可以有不同的预定义的属性。而属性的值是可以在声明该元素的时候自行指定的。在代码中使用注解,就相当于把一部分元数据从XML文件移到了代码本身之中,在一个地方管理和维护。
开发注解
在一般的开发中,只需要通过阅读相关的API文档来了解每个注解的配置参数的含义,并在代码中正确使用即可。在有些情况下,可能会需要开发自己的注解。这在库的开发中比较常见。注解的定义有点类似接口。下面的代码给出了一个简单的描述代码分工安排的注解。通过该注解可以在源代码中记录每个类或接口的分工和进度情况。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Assignment {
String assignee();
int effort();
double finished() default 0;
}
@interface用来声明一个注解,其中的每一个方法实际上是声明了一个配置参数。方法的名称就是参数的名称,返回值类型就是参数的类型。可以通过default来声明参数的默认值。在这里可以看到@Retention和@Target这样的元注解,用来声明注解本身的行为。@Retention用来声明注解的保留策略,有CLASS、RUNTIME和SOURCE这三种,分别表示注解保存在类文件、JVM运行时刻和源代码中。只有当声明为RUNTIME的时候,才能够在运行时刻通过反射API来获取到注解的信息。@Target用来声明注解可以被添加在哪些类型的元素上,如类型、方法和域等。
处理注解
在程序中添加的注解,可以在编译时刻或是运行时刻来进行处理。在编译时刻处理的时候,是分成多趟来进行的。如果在某趟处理中产生了新的Java源文件,那么就需要另外一趟处理来处理新生成的源文件。如此往复,直到没有新文件被生成为止。在完成处理之后,再对Java代码进行编译。JDK 5中提供了apt工具用来对注解进行处理。apt是一个命令行工具,与之配套的还有一套用来描述程序语义结构的Mirror API。Mirror API(com.sun.mirror./*)描述的是程序在编译时刻的静态结构。通过Mirror API可以获取到被注解的Java类型元素的信息,从而提供相应的处理逻辑。具体的处理工作交给apt工具来完成。编写注解处理器的核心是AnnotationProcessorFactory和AnnotationProcessor两个接口。后者表示的是注解处理器,而前者则是为某些注解类型创建注解处理器的工厂。
以上面的注解Assignment为例,当每个开发人员都在源代码中更新进度的话,就可以通过一个注解处理器来生成一个项目整体进度的报告。 首先是注解处理器工厂的实现。
public class AssignmentApf implements AnnotationProcessorFactory {
public AnnotationProcessor getProcessorFor(Set<AnnotationTypeDeclaration> atds,? AnnotationProcessorEnvironment env) {
if (atds.isEmpty()) {
return AnnotationProcessors.NO_OP;
}
return new AssignmentAp(env); //返回注解处理器
}
public Collection<String> supportedAnnotationTypes() {
return Collections.unmodifiableList(Arrays.asList("annotation.Assignment"));
}
public Collection<String> supportedOptions() {
return Collections.emptySet();
}
}
AnnotationProcessorFactory接口有三个方法:getProcessorFor是根据注解的类型来返回特定的注解处理器;supportedAnnotationTypes是返回该工厂生成的注解处理器所能支持的注解类型;supportedOptions用来表示所支持的附加选项。在运行apt命令行工具的时候,可以通过-A来传递额外的参数给注解处理器,如-Averbose=true。当工厂通过 supportedOptions方法声明了所能识别的附加选项之后,注解处理器就可以在运行时刻通过AnnotationProcessorEnvironment的getOptions方法获取到选项的实际值。注解处理器本身的基本实现如下所示。
public class AssignmentAp implements AnnotationProcessor {
private AnnotationProcessorEnvironment env;
private AnnotationTypeDeclaration assignmentDeclaration;
public AssignmentAp(AnnotationProcessorEnvironment env) {
this.env = env;
assignmentDeclaration = (AnnotationTypeDeclaration) env.getTypeDeclaration("annotation.Assignment");
}
public void process() {
Collection<Declaration> declarations = env.getDeclarationsAnnotatedWith(assignmentDeclaration);
for (Declaration declaration : declarations) {
processAssignmentAnnotations(declaration);
}
}
private void processAssignmentAnnotations(Declaration declaration) {
Collection<AnnotationMirror> annotations = declaration.getAnnotationMirrors();
for (AnnotationMirror mirror : annotations) {
if (mirror.getAnnotationType().getDeclaration().equals(assignmentDeclaration)) {
Map<AnnotationTypeElementDeclaration, AnnotationValue> values = mirror.getElementValues();
String assignee = (String) getAnnotationValue(values, "assignee"); //获取注解的值
}
}
}
}
注解处理器的处理逻辑都在process方法中完成。通过一个声明(Declaration)的getAnnotationMirrors方法就可以获取到该声明上所添加的注解的实际值。得到这些值之后,处理起来就不难了。
在创建好注解处理器之后,就可以通过apt命令行工具来对源代码中的注解进行处理。 命令的运行格式是apt -classpath bin -factory annotation.apt.AssignmentApf src/annotation/work//*.java,即通过-factory来指定注解处理器工厂类的名称。实际上,apt工具在完成处理之后,会自动调用javac来编译处理完成后的源代码。
JDK 5中的apt工具的不足之处在于它是Oracle提供的私有实现。在JDK 6中,通过JSR 269把自定义注解处理器这一功能进行了规范化,有了新的javax.annotation.processing这个新的API。对Mirror API也进行了更新,形成了新的javax.lang.model包。注解处理器的使用也进行了简化,不需要再单独运行apt这样的命令行工具,Java编译器本身就可以完成对注解的处理。对于同样的功能,如果用JSR 269的做法,只需要一个类就可以了。
@SupportedSourceVersion(SourceVersion.RELEASE_6)
@SupportedAnnotationTypes("annotation.Assignment")
public class AssignmentProcess extends AbstractProcessor {
private TypeElement assignmentElement;
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
Elements elementUtils = processingEnv.getElementUtils();
assignmentElement = elementUtils.getTypeElement("annotation.Assignment");
}
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
Set<? extends Element> elements = roundEnv.getElementsAnnotatedWith(assignmentElement);
for (Element element : elements) {
processAssignment(element);
}
}
private void processAssignment(Element element) {
List<? extends AnnotationMirror> annotations = element.getAnnotationMirrors();
for (AnnotationMirror mirror : annotations) {
if (mirror.getAnnotationType().asElement().equals(assignmentElement)) {
Map<? extends ExecutableElement, ? extends AnnotationValue> values = mirror.getElementValues();
String assignee = (String) getAnnotationValue(values, "assignee"); //获取注解的值
}
}
}
}
仔细比较上面两段代码,可以发现它们的基本结构是类似的。不同之处在于JDK 6中通过元注解@SupportedAnnotationTypes来声明所支持的注解类型。另外描述程序静态结构的javax.lang.model包使用了不同的类型名称。使用的时候也更加简单,只需要通过javac -processor annotation.pap.AssignmentProcess Demo1.java这样的方式即可。
上面介绍的这两种做法都是在编译时刻进行处理的。而有些时候则需要在运行时刻来完成对注解的处理。这个时候就需要用到Java的反射API。反射API提供了在运行时刻读取注解信息的支持。不过前提是注解的保留策略声明的是运行时。Java反射API的AnnotatedElement接口提供了获取类、方法和域上的注解的实用方法。比如获取到一个Class类对象之后,通过getAnnotation方法就可以获取到该类上添加的指定注解类型的注解。
实例分析
下面通过一个具体的实例来分析说明在实践中如何来使用和处理注解。假定有一个公司的雇员信息系统,从访问控制的角度出发,对雇员的工资的更新只能由具有特定角色的用户才能完成。考虑到访问控制需求的普遍性,可以定义一个注解来让开发人员方便的在代码中声明访问控制权限。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface RequiredRoles {
String[] value();
}
下一步则是如何对注解进行处理,这里使用的Java的反射API并结合动态代理。下面是动态代理中的InvocationHandler接口的实现。
public class AccessInvocationHandler implements InvocationHandler {
final T accessObj;
public AccessInvocationHandler(T accessObj) {
this.accessObj = accessObj;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
RequiredRoles annotation = method.getAnnotation(RequiredRoles.class); //通过反射API获取注解
if (annotation != null) {
String[] roles = annotation.value();
String role = AccessControl.getCurrentRole();
if (!Arrays.asList(roles).contains(role)) {
throw new AccessControlException("The user is not allowed to invoke this method.");
}
}
return method.invoke(accessObj, args);
}
}
在具体使用的时候,首先要通过Proxy.newProxyInstance方法创建一个EmployeeGateway的接口的代理类,使用该代理类来完成实际的操作。
参考资料
感谢张凯峰对本文的策划和审校。
来源: [http://www.infoq.com/cn/articles/cf-java-annotation](http://www.infoq.com/cn/articles/cf-java-annotation)
Tomcat源码分析
一、架构
下面谈谈我对Tomcat架构的理解
总体架构:
1、面向组件架构
2、基于JMX
3、事件侦听
1)面向组件架构
tomcat代码看似很庞大,但从结构上看却很清晰和简单,它主要由一堆组件组成,如Server、Service、Connector等,并基于JMX管理这些组件,另外实现以上接口的组件也实现了代表生存期的接口Lifecycle,使其组件履行固定的生存期,在其整个生存期的过程中通过事件侦听LifecycleEvent实现扩展。Tomcat的核心类图如下所示:
![]()
1、Catalina:与开始/关闭shell脚本交互的主类,因此如果要研究启动和关闭的过程,就从这个类开始看起。
2、Server:是整个Tomcat组件的容器,包含一个或多个Service。
3、Service:Service是包含Connector和Container的集合,Service用适当的Connector接收用户的请求,再发给相应的Container来处理。
4、Connector:实现某一协议的连接器,如默认的有实现HTTP、HTTPS、AJP协议的。
5、Container:可以理解为处理某类型请求的容器,处理的方式一般为把处理请求的处理器包装为Valve对象,并按一定顺序放入类型为Pipeline的管道里。Container有多种子类型:Engine、Host、Context和Wrapper,这几种子类型Container依次包含,处理不同粒度的请求。另外Container里包含一些基础服务,如Loader、Manager和Realm。
6、Engine:Engine包含Host和Context,接到请求后仍给相应的Host在相应的Context里处理。
7、Host:就是我们所理解的虚拟主机。
8、Context:就是我们所部属的具体Web应用的上下文,每个请求都在是相应的上下文里处理的
9、Wrapper:Wrapper是针对每个Servlet的Container,每个Servlet都有相应的Wrapper来管理。
可以看出Server、Service、Connector、Container、Engine、Host、Context和Wrapper这些核心组件的作用范围是逐层递减,并逐层包含。
下面就是些被Container所用的基础组件:
1、Loader:是被Container用来载入各种所需的Class。
2、Manager:是被Container用来管理Session池。
3、Realm:是用来处理安全里授权与认证。
分析完核心类后,再看看Tomcat启动的过程,Tomcat启动的时序图如下所示:
![]()
从上图可以看出,Tomcat启动分为init和start两个过程,核心组件都实现了Lifecycle接口,都需实现start方法,因此在start过程中就是从Server开始逐层调用子组件的start过程。
2)基于JMX
Tomcat会为每个组件进行注册过程,通过Registry管理起来,而Registry是基于JMX来实现的,因此在看组件的init和start过程实际上就是初始化MBean和触发MBean的start方法,会大量看到形如:
Registry.getRegistry(null, null).invoke(mbeans, "init", false);
Registry.getRegistry(null, null).invoke(mbeans, "start", false);
这样的代码,这实际上就是通过JMX管理各种组件的行为和生命期。
3)事件侦听
各个组件在其生命期中会有各种各样行为,而这些行为都有触发相应的事件,Tomcat就是通过侦听这些时间达到对这些行为进行扩展的目的。在看组件的init和start过程中会看到大量如:
lifecycle.fireLifecycleEvent(AFTER_START_EVENT, null);
这样的代码,这就是对某一类型事件的触发,如果你想在其中加入自己的行为,就只用注册相应类型的事件即可。
二、一次完整请求的里里外外
前几天分析了一下Tomcat的架构和启动过程,今天开始研究它的运转机制。Tomcat最本质就是个能运行JSP/Servlet的Web服务器 ,因此最典型的应用就是用户通过浏览器访问服务器,Tomcat接收到请求后转发给Servlet,由Servlet处理完后,把结果返回给客户端。今天就专门解析一下这么一个完整的请求的内部机理。
通过DEBUG,一路跟下来,发现Tomcat处理请求的核心过程是以下几点:
1、启动的时候启动预支持协议的Endpoint,Endpoint会起专门的线程监听相应协议的请求,默认的情况下,会启动JIoEndpoint,JIoEndpoint基于Java ServerSocket接收Http的请求
2、ServerSocket接收到客户端请求的Socket后,一路包装,并一路从Host一直传递到Wrapper,再请求到相应的Servlet
下面将重点解析以上两个过程。
通过以前的分析(Tomcat源码分析一)可知道当Tomcat启动的时候会启动Connector,此时Connector会通过ProtocolHandler把Endpoint启动起来。默认情况下,Tomcat会启动两种Connector,分别是Http协议和AJP协议的,依次对应Http11Protocol和AjpProtocol,两者都是启动JIoEndpoint。下面看看JIoEndpoint的start方法:
public void start() throws Exception {
// Initialize socket if not done before
if (!initialized) {
init();
}
if (!running) {
running = true;
paused = false;
// Create worker collection
if (getExecutor() == null) {
createExecutor();
}
// Start acceptor threads
for (int i = 0; i < acceptorThreadCount; i++) {
Thread acceptorThread = new Thread(new Acceptor(), getName() + "-Acceptor-" + i);
acceptorThread.setPriority(threadPriority);
acceptorThread.setDaemon(getDaemon());
acceptorThread.start();
}
}
}
public void start() throws Exception {
// Initialize socket if not done before
if (!initialized) {
init();
}
if (!running) {
running = true;
paused = false;
// Create worker collection
if (getExecutor() == null) {
createExecutor();
}
// Start acceptor threads
for (int i = 0; i < acceptorThreadCount; i++) {
Thread acceptorThread = new Thread(new Acceptor(), getName() + "-Acceptor-" + i);
acceptorThread.setPriority(threadPriority);
acceptorThread.setDaemon(getDaemon());
acceptorThread.start();
}
}
}
以上代码很清晰地表示启动acceptorThreadCount个线程,每个线程由Acceptor代理,具体看看Acceptor的run方法:
public void run() {
// Loop until we receive a shutdown command
while (running) {
// Loop if endpoint is paused
while (paused) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// Ignore
}
}
// Accept the next incoming connection from the server socket
try {
Socket socket = serverSocketFactory.acceptSocket(serverSocket);
serverSocketFactory.initSocket(socket);
// Hand this socket off to an appropriate processor
if (!processSocket(socket)) {
// Close socket right away
try {
socket.close();
} catch (IOException e) {
// Ignore
}
}
}catch ( IOException x ) {
if ( running ) log.error(sm.getString("endpoint.accept.fail"), x);
} catch (Throwable t) {
log.error(sm.getString("endpoint.accept.fail"), t);
}
// The processor will recycle itself when it finishes
}
}
public void run() {
// Loop until we receive a shutdown command
while (running) {
// Loop if endpoint is paused
while (paused) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// Ignore
}
}
// Accept the next incoming connection from the server socket
try {
Socket socket = serverSocketFactory.acceptSocket(serverSocket);
serverSocketFactory.initSocket(socket);
// Hand this socket off to an appropriate processor
if (!processSocket(socket)) {
// Close socket right away
try {
socket.close();
} catch (IOException e) {
// Ignore
}
}
}catch ( IOException x ) {
if ( running ) log.error(sm.getString("endpoint.accept.fail"), x);
} catch (Throwable t) {
log.error(sm.getString("endpoint.accept.fail"), t);
}
// The processor will recycle itself when it finishes
}
}
由此可得到这么一个结论:Tomcat就是通过ServerSocket监听Socket的方式来接收客户端请求的。具体代码就无需我解析了,稍微了解Java net的人都能看懂以上代码,Tomcat就是用最标准和最基础的Socket调用方法来处理网络请求的。找到处理请求的源头后下面要做的是事情就简单了,打好断点,在浏览器里请求一个最简单的Hello world,一路debug下去。一路跟下来,主流程的时序图如下所示:
![]()
从上图可知,以上过程可分解成以下三个最主要的核心点:
1、基于Http1.1协议对Socket的解析和包装
2、StandardEngineValve、StandardHostValve、StandardContextValve和StandardWrapperValve四种Valve的一路inoke。四种不同层次的Valve做了不同层次的处理和封装
3、基于责任链模式ApplicationFilterChain实现Filter拦截和实际Servlet的请求
以上三个核心点都是内容非常丰富的可研究点,会在以后几天逐一进行剖析。
三、可携带状态的线程池
最近想实现一个可携带状态的线程池,具体需求就是池中的线程被用来处理某种信息,而此信息可视为线程所依赖的外部状态。如果用简单的线程池来实现,线程初始化时就得赋予某些信息,使得线程无法被再次利用。在看老版Tomcat的源码时,找到了答案,其实现思路主要是利用了线程的等待和唤起,HttpProcessor的实现正好基于此思路,时序图如下所示:
![]()
初始化HttpProcessor线程时,没法赋予所需的Socket对象,因为如果在初始化阶段就赋予Socket会导致此线程没法回收用来处理其他Socket。因此,在HttpProcessor的run阶段,先把线程给wait住,具体在await方法里体现,代码如下所示:
///
/* Await a newly assigned Socket from our Connector, or
null
/ if we are supposed to shut down.
//
private synchronized Socket await() {
// Wait for the Connector to provide a new Socket
while (!available) {
try {
wait();
} catch (InterruptedException e) {
}
}
// Notify the Connector that we have received this Socket
Socket socket = this.socket;
available = false;
notifyAll();
if ((debug >= 1) && (socket != null))
log(" The incoming request has been awaited");
return (socket);
}
///
/* Await a newly assigned Socket from our Connector, or
null
/ if we are supposed to shut down.
//
private synchronized Socket await() {
// Wait for the Connector to provide a new Socket
while (!available) {
try {
wait();
} catch (InterruptedException e) {
}
}
// Notify the Connector that we have received this Socket
Socket socket = this.socket;
available = false;
notifyAll();
if ((debug >= 1) && (socket != null))
log(" The incoming request has been awaited");
return (socket);
}
当HttpConnector调用HttpProcessor.assign(socket)方法时,会给此线程赋予Socket对象,并唤起此线程,使其继续执行,assign方法的源码如下所示:
///
/ Process an incoming TCP/IP connection on the specified socket. Any
/ exception that occurs during processing must be logged and swallowed.
/
*NOTE
: This method is called from our Connector's thread. We
/* must assign it to our own thread so that multiple simultaneous
/ requests can be handled.
/
/ @param socket TCP socket to process
//
synchronized void assign(Socket socket) {
// Wait for the Processor to get the previous Socket
while (available) {
try {
wait();
} catch (InterruptedException e) {
}
}
// Store the newly available Socket and notify our thread
this.socket = socket;
available = true;
notifyAll();
if ((debug >= 1) && (socket != null))
log(" An incoming request is being assigned");
}
///
/ Process an incoming TCP/IP connection on the specified socket. Any
/ exception that occurs during processing must be logged and swallowed.
/
*NOTE
: This method is called from our Connector's thread. We
/* must assign it to our own thread so that multiple simultaneous
/ requests can be handled.
/
/ @param socket TCP socket to process
//
synchronized void assign(Socket socket) {
// Wait for the Processor to get the previous Socket
while (available) {
try {
wait();
} catch (InterruptedException e) {
}
}
// Store the newly available Socket and notify our thread
this.socket = socket;
available = true;
notifyAll();
if ((debug >= 1) && (socket != null))
log(" An incoming request is being assigned");
}
线程被唤起和赋予socket对象后,继续执行核心的process方法,HttpProcessor.run的完整源码如下所示:
///
/ The background thread that listens for incoming TCP/IP connections and
/ hands them off to an appropriate processor.
/*/
public void run() {
// Process requests until we receive a shutdown signal
while (!stopped) {
// Wait for the next socket to be assigned
Socket socket = await();
if (socket == null)
continue;
// Process the request from this socket
try {
process(socket);
} catch (Throwable t) {
log("process.invoke", t);
}
// Finish up this request
connector.recycle(this);
}
// Tell threadStop() we have shut ourselves down successfully
synchronized (threadSync) {
threadSync.notifyAll();
}
}
///
/ The background thread that listens for incoming TCP/IP connections and
/ hands them off to an appropriate processor.
/*/
public void run() {
// Process requests until we receive a shutdown signal
while (!stopped) {
// Wait for the next socket to be assigned
Socket socket = await();
if (socket == null)
continue;
// Process the request from this socket
try {
process(socket);
} catch (Throwable t) {
log("process.invoke", t);
}
// Finish up this request
connector.recycle(this);
}
// Tell threadStop() we have shut ourselves down successfully
synchronized (threadSync) {
threadSync.notifyAll();
}
}
四、Request和Response处理的全过程
从Tomcat源码分析(二)可知,用户的一个请求会经过n个环节的处理,最后到达开发人员写的Servlet,传给Servlet也就是HttpServletRequest和HttpServletResponse,因此可以认为这一路走下来无非就是把最原始的Socket包装成Servlet里用到的HttpServletRequest和HttpServletResponse,只不过每个环节完成的包装功能和部分不一样而已,信息流如下图所示:
![]()
其中,Request与Response的类图如下所示:
![]()
org.apache.coyote.Request和org.apache.coyote.Response是Tomcat内部使用的,不提供给开发者调用,类是final类型的。下面结合一次完整请求的时序图来看看从Socket到org.apache.catalina.connector.Request的加工过程:
![]()
由上图可见,Request的解析和加工过程不是在一个方法里搞定,而是信息流动过程中逐步解析的,不同层次的处理器解析不同层次的信息,在解析过程同时做了些判断和拦截的工作,比如当发现是要访问WEB-INF的资源,会直接返回错误给客户端等等。
来源: [http://www.uml.org.cn/j2ee/201306285.asp](http://www.uml.org.cn/j2ee/201306285.asp)
深入分析 Java 中的中文编码问题
作者:许令波 , 发布于2011-07-27 , IBM 简介: 编码问题一直困扰着开发人员,尤其在 Java 中更加明显,因为 Java 是跨平台语言,不同平台之间编码之间的切换较多。本文将向你详细介绍 Java 中编码问题出现的根本原因,你将了解到:Java 中经常遇到的几种编码格式的区别;Java 中经常需要编码的场景;出现中文问题的原因分析;在开发 Java web 程序时可能会存在编码的几个地方,一个 HTTP 请求怎么控制编码格式?如何避免出现中文问题?
几种常见的编码格式
为什么要编码
不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言。由于人类的语言有太多,因而表示这些语言的符号太多,无法用计算机中一个基本的存储单元—— byte 来表示,因而必须要经过拆分或一些翻译工作,才能让计算机能理解。我们可以把计算机能够理解的语言假定为英语,其它语言要能够在计算机中使用必须经过一次翻译,把它翻译成英语。这个翻译的过程就是编码。所以可以想象只要不是说英语的国家要能够使用计算机就必须要经过编码。这看起来有些霸道,但是这就是现状,这也和我们国家现在在大力推广汉语一样,希望其它国家都会说汉语,以后其它的语言都翻译成汉语,我们可以把计算机中存储信息的最小单位改成汉字,这样我们就不存在编码问题了。
所以总的来说,编码的原因可以总结为:
- 计算机中存储信息的最小单元是一个字节即 8 个 bit,所以能表示的字符范围是 0~255 个
- 人类要表示的符号太多,无法用一个字节来完全表示
- 要解决这个矛盾必须需要一个新的数据结构 char,从 char 到 byte 必须编码
如何“翻译”
明白了各种语言需要交流,经过翻译是必要的,那又如何来翻译呢?计算中提拱了多种翻译方式,常见的有 ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16 等。它们都可以被看作为字典,它们规定了转化的规则,按照这个规则就可以让计算机正确的表示我们的字符。目前的编码格式很多,例如 GB2312、GBK、UTF-8、UTF-16 这几种格式都可以表示一个汉字,那我们到底选择哪种编码格式来存储汉字呢?这就要考虑到其它因素了,是存储空间重要还是编码的效率重要。根据这些因素来正确选择编码格式,下面简要介绍一下这几种编码格式。
学过计算机的人都知道 ASCII 码,总共有 128 个,用一个字节的低 7 位表示,0~31 是控制字符如换行回车删除等;32~126 是打印字符,可以通过键盘输入并且能够显示出来。
128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所有应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。
它的全称是《信息交换用汉字编码字符集 基本集》,它是双字节编码,总的编码范围是 A1-F7,其中从 A1-A9 是符号区,总共包含 682 个符号,从 B0-F7 是汉字区,包含 6763 个汉字。
全称叫《汉字内码扩展规范》,是国家技术监督局为 windows95 所制定的新的汉字内码规范,它的出现是为了扩展 GB2312,加入更多的汉字,它的编码范围是 8140~FEFE(去掉 XX7F)总共有 23940 个码位,它能表示 21003 个汉字,它的编码是和 GB2312 兼容的,也就是说用 GB2312 编码的汉字可以用 GBK 来解码,并且不会有乱码。
全称是《信息交换用汉字编码字符集》,是我国的强制标准,它可能是单字节、双字节或者四字节编码,它的编码与 GB2312 编码兼容,这个虽然是国家标准,但是实际应用系统中使用的并不广泛。
说到 UTF 必须要提到 Unicode(Universal Code 统一码),ISO 试图想创建一个全新的超语言字典,世界上所有的语言都可以通过这本字典来相互翻译。可想而知这个字典是多么的复杂,关于 Unicode 的详细规范可以参考相应文档。Unicode 是 Java 和 XML 的基础,下面详细介绍 Unicode 在计算机中的存储形式。
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。
UTF-16 统一采用两个字节表示一个字符,虽然在表示上非常简单方便,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在要两个字节表示,存储空间放大了一倍,在现在的网络带宽还非常有限的今天,这样会增大网络传输的流量,而且也没必要。而 UTF-8 采用了一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以是由 1~6 个字节组成。
UTF-8 有以下编码规则:
- 如果一个字节,最高位(第 8 位)为 0,表示这是一个 ASCII 字符(00 - 7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
- 如果一个字节,以 11 开头,连续的 1 的个数暗示这个字符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字符的首字节。
- 如果一个字节,以 10 开始,表示它不是首字节,需要向前查找才能得到当前字符的首字节
Java 中需要编码的场景
前面描述了常见的几种编码格式,下面将介绍 Java 中如何处理对编码的支持,什么场合中需要编码。
I/O 操作中存在的编码
我们知道涉及到编码的地方一般都在字符到字节或者字节到字符的转换上,而需要这种转换的场景主要是在 I/O 的时候,这个 I/O 包括磁盘 I/O 和网络 I/O,关于网络 I/O 部分在后面将主要以 Web 应用为例介绍。下图是 Java 中处理 I/O 问题的接口:
![]()
Reader 类是 Java 的 I/O 中读字符的父类,而 InputStream 类是读字节的父类,InputStreamReader 类就是关联字节到字符的桥梁,它负责在 I/O 过程中处理读取字节到字符的转换,而具体字节到字符的解码实现它由 StreamDecoder 去实现,在 StreamDecoder 解码过程中必须由用户指定 Charset 编码格式。值得注意的是如果你没有指定 Charset,将使用本地环境中的默认字符集,例如在中文环境中将使用 GBK 编码。
写的情况也是类似,字符的父类是 Writer,字节的父类是 OutputStream,通过 OutputStreamWriter 转换字符到字节。如下图所示:
![]()
同样 StreamEncoder 类负责将字符编码成字节,编码格式和默认编码规则与解码是一致的。
如下面一段代码,实现了文件的读写功能:
清单 1.I/O 涉及的编码示例
String file = "c:/stream.txt";
String charset = "UTF-8";
// 写字符换转成字节流
FileOutputStream outputStream = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(
outputStream, charset);
try {
writer.write("这是要保存的中文字符");
} finally {
writer.close();
}
// 读取字节转换成字符
FileInputStream inputStream = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(
inputStream, charset);
StringBuffer buffer = new StringBuffer();
char[] buf = new char[64];
int count = 0;
try {
while ((count = reader.read(buf)) != -1) {
buffer.append(buffer, 0, count);
}
} finally {
reader.close();
}
在我们的应用程序中涉及到 I/O 操作时只要注意指定统一的编解码 Charset 字符集,一般不会出现乱码问题,有些应用程序如果不注意指定字符编码,中文环境中取操作系统默认编码,如果编解码都在中文环境中,通常也没问题,但是还是强烈的不建议使用操作系统的默认编码,因为这样,你的应用程序的编码格式就和运行环境绑定起来了,在跨环境下很可能出现乱码问题。
内存中操作中的编码
在 Java 开发中除了 I/O 涉及到编码外,最常用的应该就是在内存中进行字符到字节的数据类型的转换,Java 中用 String 表示字符串,所以 String 类就提供转换到字节的方法,也支持将字节转换为字符串的构造函数。如下代码示例:
String s = "这是一段中文字符串";
byte[] b = s.getBytes("UTF-8");
String n = new String(b,"UTF-8");
另外一个是已经被被废弃的 ByteToCharConverter 和 CharToByteConverter 类,它们分别提供了 convertAll 方法可以实现 byte[] 和 char[] 的互转。如下代码所示:
ByteToCharConverter charConverter = ByteToCharConverter.getConverter("UTF-8");
char c[] = charConverter.convertAll(byteArray);
CharToByteConverter byteConverter = CharToByteConverter.getConverter("UTF-8");
byte[] b = byteConverter.convertAll(c);
这两个类已经被 Charset 类取代,Charset 提供 encode 与 decode 分别对应 char[] 到 byte[] 的编码和 byte[] 到 char[] 的解码。如下代码所示:
Charset charset = Charset.forName("UTF-8");
ByteBuffer byteBuffer = charset.encode(string);
CharBuffer charBuffer = charset.decode(byteBuffer);
编码与解码都在一个类中完成,通过 forName 设置编解码字符集,这样更容易统一编码格式,比 ByteToCharConverter 和 CharToByteConverter 类更方便。
Java 中还有一个 ByteBuffer 类,它提供一种 char 和 byte 之间的软转换,它们之间转换不需要编码与解码,只是把一个 16bit 的 char 格式,拆分成为 2 个 8bit 的 byte 表示,它们的实际值并没有被修改,仅仅是数据的类型做了转换。如下代码所以:
ByteBuffer heapByteBuffer = ByteBuffer.allocate(1024);
ByteBuffer byteBuffer = heapByteBuffer.putChar(c);
以上这些提供字符和字节之间的相互转换只要我们设置编解码格式统一一般都不会出现问题。
Java 中如何编解码
前面介绍了几种常见的编码格式,这里将以实际例子介绍 Java 中如何实现编码及解码,下面我们以“I am 君山”这个字符串为例介绍 Java 中如何把它以 ISO-8859-1、GB2312、GBK、UTF-16、UTF-8 编码格式进行编码的。
清单 2.String 编码
public static void encode() {
String name = "I am 君山";
toHex(name.toCharArray());
try {
byte[] iso8859 = name.getBytes("ISO-8859-1");
toHex(iso8859);
byte[] gb2312 = name.getBytes("GB2312");
toHex(gb2312);
byte[] gbk = name.getBytes("GBK");
toHex(gbk);
byte[] utf16 = name.getBytes("UTF-16");
toHex(utf16);
byte[] utf8 = name.getBytes("UTF-8");
toHex(utf8);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
我们把 name 字符串按照前面说的几种编码格式进行编码转化成 byte 数组,然后以 16 进制输出,我们先看一下 Java 是如何进行编码的。
下面是 Java 中编码需要用到的类图
图 1. Java 编码类图
![]()
首先根据指定的 charsetName 通过 Charset.forName(charsetName) 设置 Charset 类,然后根据 Charset 创建 CharsetEncoder 对象,再调用 CharsetEncoder.encode 对字符串进行编码,不同的编码类型都会对应到一个类中,实际的编码过程是在这些类中完成的。下面是 String. getBytes(charsetName) 编码过程的时序图
图 2.Java 编码时序图
![]()
从上图可以看出根据 charsetName 找到 Charset 类,然后根据这个字符集编码生成 CharsetEncoder,这个类是所有字符编码的父类,针对不同的字符编码集在其子类中定义了如何实现编码,有了 CharsetEncoder 对象后就可以调用 encode 方法去实现编码了。这个是 String.getBytes 编码方法,其它的如 StreamEncoder 中也是类似的方式。下面看看不同的字符集是如何将前面的字符串编码成 byte 数组的?
如字符串“I am 君山”的 char 数组为 49 20 61 6d 20 541b 5c71,下面把它按照不同的编码格式转化成相应的字节。
按照 ISO-8859-1 编码
字符串“I am 君山”用 ISO-8859-1 编码,下面是编码结果:
![]()
从上图看出 7 个 char 字符经过 ISO-8859-1 编码转变成 7 个 byte 数组,ISO-8859-1 是单字节编码,中文“君山”被转化成值是 3f 的 byte。3f 也就是“?”字符,所以经常会出现中文变成“?”很可能就是错误的使用了 ISO-8859-1 这个编码导致的。中文字符经过 ISO-8859-1 编码会丢失信息,通常我们称之为“黑洞”,它会把不认识的字符吸收掉。由于现在大部分基础的 Java 框架或系统默认的字符集编码都是 ISO-8859-1,所以很容易出现乱码问题,后面将会分析不同的乱码形式是怎么出现的。
按照 GB2312 编码
字符串“I am 君山”用 GB2312 编码,下面是编码结果:
![]()
GB2312 对应的 Charset 是 sun.nio.cs.ext. EUC_CN 而对应的 CharsetDecoder 编码类是 sun.nio.cs.ext. DoubleByte,GB2312 字符集有一个 char 到 byte 的码表,不同的字符编码就是查这个码表找到与每个字符的对应的字节,然后拼装成 byte 数组。查表的规则如下:
c2b[c2bIndex[char >> 8] + (char & 0xff)]
如果查到的码位值大于 oxff 则是双字节,否则是单字节。双字节高 8 位作为第一个字节,低 8 位作为第二个字节,如下代码所示:
if (bb > 0xff) { // DoubleByte
if (dl - dp < 2)
return CoderResult.OVERFLOW;
da[dp++] = (byte) (bb >> 8);
da[dp++] = (byte) bb;
} else { // SingleByte
if (dl - dp < 1)
return CoderResult.OVERFLOW;
da[dp++] = (byte) bb;
}
从上图可以看出前 5 个字符经过编码后仍然是 5 个字节,而汉字被编码成双字节,在第一节中介绍到 GB2312 只支持 6763 个汉字,所以并不是所有汉字都能够用 GB2312 编码。
按照 GBK 编码
字符串“I am 君山”用 GBK 编码,下面是编码结果:
![]()
你可能已经发现上图与 GB2312 编码的结果是一样的,没错 GBK 与 GB2312 编码结果是一样的,由此可以得出 GBK 编码是兼容 GB2312 编码的,它们的编码算法也是一样的。不同的是它们的码表长度不一样,GBK 包含的汉字字符更多。所以只要是经过 GB2312 编码的汉字都可以用 GBK 进行解码,反过来则不然。
按照 UTF-16 编码
字符串“I am 君山”用 UTF-16 编码,下面是编码结果:
![]()
用 UTF-16 编码将 char 数组放大了一倍,单字节范围内的字符,在高位补 0 变成两个字节,中文字符也变成两个字节。从 UTF-16 编码规则来看,仅仅将字符的高位和地位进行拆分变成两个字节。特点是编码效率非常高,规则很简单,由于不同处理器对 2 字节处理方式不同,Big-endian(高位字节在前,低位字节在后)或 Little-endian(低位字节在前,高位字节在后)编码,所以在对一串字符串进行编码是需要指明到底是 Big-endian 还是 Little-endian,所以前面有两个字节用来保存 BYTE_ORDER_MARK 值,UTF-16 是用定长 16 位(2 字节)来表示的 UCS-2 或 Unicode 转换格式,通过代理对来访问 BMP 之外的字符编码。
按照 UTF-8 编码
字符串“I am 君山”用 UTF-8 编码,下面是编码结果:
![]()
UTF-16 虽然编码效率很高,但是对单字节范围内字符也放大了一倍,这无形也浪费了存储空间,另外 UTF-16 采用顺序编码,不能对单个字符的编码值进行校验,如果中间的一个字符码值损坏,后面的所有码值都将受影响。而 UTF-8 这些问题都不存在,UTF-8 对单字节范围内字符仍然用一个字节表示,对汉字采用三个字节表示。它的编码规则如下:
清单 3.UTF-8 编码代码片段
private CoderResult encodeArrayLoop(CharBuffer src,
ByteBuffer dst){
char[] sa = src.array();
int sp = src.arrayOffset() + src.position();
int sl = src.arrayOffset() + src.limit();
byte[] da = dst.array();
int dp = dst.arrayOffset() + dst.position();
int dl = dst.arrayOffset() + dst.limit();
int dlASCII = dp + Math.min(sl - sp, dl - dp);
// ASCII only loop
while (dp < dlASCII && sa[sp] < '\u0080')
da[dp++] = (byte) sa[sp++];
while (sp < sl) {
char c = sa[sp];
if (c < 0x80) {
// Have at most seven bits
if (dp >= dl)
return overflow(src, sp, dst, dp);
da[dp++] = (byte)c;
} else if (c < 0x800) {
// 2 bytes, 11 bits
if (dl - dp < 2)
return overflow(src, sp, dst, dp);
da[dp++] = (byte)(0xc0 | (c >> 6));
da[dp++] = (byte)(0x80 | (c & 0x3f));
} else if (Character.isSurrogate(c)) {
// Have a surrogate pair
if (sgp == null)
sgp = new Surrogate.Parser();
int uc = sgp.parse(c, sa, sp, sl);
if (uc < 0) {
updatePositions(src, sp, dst, dp);
return sgp.error();
}
if (dl - dp < 4)
return overflow(src, sp, dst, dp);
da[dp++] = (byte)(0xf0 | ((uc >> 18)));
da[dp++] = (byte)(0x80 | ((uc >> 12) & 0x3f));
da[dp++] = (byte)(0x80 | ((uc >> 6) & 0x3f));
da[dp++] = (byte)(0x80 | (uc & 0x3f));
sp++; // 2 chars
} else {
// 3 bytes, 16 bits
if (dl - dp < 3)
return overflow(src, sp, dst, dp);
da[dp++] = (byte)(0xe0 | ((c >> 12)));
da[dp++] = (byte)(0x80 | ((c >> 6) & 0x3f));
da[dp++] = (byte)(0x80 | (c & 0x3f));
}
sp++;
}
updatePositions(src, sp, dst, dp);
return CoderResult.UNDERFLOW;
}
UTF-8 编码与 GBK 和 GB2312 不同,不用查码表,所以在编码效率上 UTF-8 的效率会更好,所以在存储中文字符时 UTF-8 编码比较理想。
几种编码格式的比较
对中文字符后面四种编码格式都能处理,GB2312 与 GBK 编码规则类似,但是 GBK 范围更大,它能处理所有汉字字符,所以 GB2312 与 GBK 比较应该选择 GBK。UTF-16 与 UTF-8 都是处理 Unicode 编码,它们的编码规则不太相同,相对来说 UTF-16 编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间快速切换,如 Java 的内存编码就是采用 UTF-16 编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,想比较而言 UTF-8 更适合网络传输,对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面其它字符,在编码效率上介于 GBK 和 UTF-16 之间,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
Java Web 涉及到的编码
对于使用中文来说,有 I/O 的地方就会涉及到编码,前面已经提到了 I/O 操作会引起编码,而大部分 I/O 引起的乱码都是网络 I/O,因为现在几乎所有的应用程序都涉及到网络操作,而数据经过网络传输都是以字节为单位的,所以所有的数据都必须能够被序列化为字节。在 Java 中数据被序列化必须继承 Serializable 接口。
这里有一个问题,你是否认真考虑过一段文本它的实际大小应该怎么计算,我曾经碰到过一个问题:就是要想办法压缩 Cookie 大小,减少网络传输量,当时有选择不同的压缩算法,发现压缩后字符数是减少了,但是并没有减少字节数。所谓的压缩只是将多个单字节字符通过编码转变成一个多字节字符。减少的是 String.length(),而并没有减少最终的字节数。例如将“ab”两个字符通过某种编码转变成一个奇怪的字符,虽然字符数从两个变成一个,但是如果采用 UTF-8 编码这个奇怪的字符最后经过编码可能又会变成三个或更多的字节。同样的道理比如整型数字 1234567 如果当成字符来存储,采用 UTF-8 来编码占用 7 个 byte,采用 UTF-16 编码将会占用 14 个 byte,但是把它当成 int 型数字来存储只需要 4 个 byte 来存储。所以看一段文本的大小,看字符本身的长度是没有意义的,即使是一样的字符采用不同的编码最终存储的大小也会不同,所以从字符到字节一定要看编码类型。
另外一个问题,你是否考虑过,当我们在电脑中某个文本编辑器里输入某个汉字时,它到底是怎么表示的?我们知道,计算机里所有的信息都是以 01 表示的,那么一个汉字,它到底是多少个 0 和 1 呢?我们能够看到的汉字都是以字符形式出现的,例如在 Java 中“淘宝”两个字符,它在计算机中的数值 10 进制是 28120 和 23453,16 进制是 6bd8 和 5d9d,也就是这两个字符是由这两个数字唯一表示的。Java 中一个 char 是 16 个 bit 相当于两个字节,所以两个汉字用 char 表示在内存中占用相当于四个字节的空间。
这两个问题搞清楚后,我们看一下 Java Web 中那些地方可能会存在编码转换?
用户从浏览器端发起一个 HTTP 请求,需要存在编码的地方是 URL、Cookie、Parameter。服务器端接受到 HTTP 请求后要解析 HTTP 协议,其中 URI、Cookie 和 POST 表单参数需要解码,服务器端可能还需要读取数据库中的数据,本地或网络中其它地方的文本文件,这些数据都可能存在编码问题,当 Servlet 处理完所有请求的数据后,需要将这些数据再编码通过 Socket 发送到用户请求的浏览器里,再经过浏览器解码成为文本。这些过程如下图所示:
图 3. 一次 HTTP 请求的编码示例
![]()
如上图所示一次 HTTP 请求设计到很多地方需要编解码,它们编解码的规则是什么?下面将会重点阐述一下:
URL 的编解码
用户提交一个 URL,这个 URL 中可能存在中文,因此需要编码,如何对这个 URL 进行编码?根据什么规则来编码?有如何来解码?如下图一个 URL:
图 4.URL 的几个组成部分
![]()
上图中以 Tomcat 作为 Servlet Engine 为例,它们分别对应到下面这些配置文件中:
Port 对应在 Tomcat 的 中配置,而 Context Path 在 中配置,Servlet Path 在 Web 应用的 web.xml 中的
junshanExample
/servlets/servlet//*
中配置,PathInfo 是我们请求的具体的 Servlet,QueryString 是要传递的参数,注意这里是在浏览器里直接输入 URL 所以是通过 Get 方法请求的,如果是 POST 方法请求的话,QueryString 将通过表单方式提交到服务器端,这个将在后面再介绍。
上图中 PathInfo 和 QueryString 出现了中文,当我们在浏览器中直接输入这个 URL 时,在浏览器端和服务端会如何编码和解析这个 URL 呢?为了验证浏览器是怎么编码 URL 的我们选择 FireFox 浏览器并通过 HTTPFox 插件观察我们请求的 URL 的实际的内容,以下是 URL:HTTP://localhost:8080/examples/servlets/servlet/ 君山 ?author= 君山在中文 FireFox3.6.12 的测试结果
图 5. HTTPFox 的测试结果
![]()
君山的编码结果分别是:e5 90 9b e5 b1 b1,be fd c9 bd,查阅上一届的编码可知,PathInfo 是 UTF-8 编码而 QueryString 是经过 GBK 编码,至于为什么会有“%”?查阅 URL 的编码规范 RFC3986 可知浏览器编码 URL 是将非 ASCII 字符按照某种编码格式编码成 16 进制数字然后将每个 16 进制表示的字节前加上“%”,所以最终的 URL 就成了上图的格式了。
默认情况下中文 IE 最终的编码结果也是一样的,不过 IE 浏览器可以修改 URL 的编码格式在选项 -> 高级 -> 国际里面的发送 UTF-8 URL 选项可以取消。
从上面测试结果可知浏览器对 PathInfo 和 QueryString 的编码是不一样的,不同浏览器对 PathInfo 也可能不一样,这就对服务器的解码造成很大的困难,下面我们以 Tomcat 为例看一下,Tomcat 接受到这个 URL 是如何解码的。
解析请求的 URL 是在 org.apache.coyote.HTTP11.InternalInputBuffer 的 parseRequestLine 方法中,这个方法把传过来的 URL 的 byte[] 设置到 org.apache.coyote.Request 的相应的属性中。这里的 URL 仍然是 byte 格式,转成 char 是在org.apache.catalina.connector.CoyoteAdapter 的 convertURI 方法中完成的:
protected void convertURI(MessageBytes uri, Request request)
throws Exception {
ByteChunk bc = uri.getByteChunk();
int length = bc.getLength();
CharChunk cc = uri.getCharChunk();
cc.allocate(length, -1);
String enc = connector.getURIEncoding();
if (enc != null) {
B2CConverter conv = request.getURIConverter();
try {
if (conv == null) {
conv = new B2CConverter(enc);
request.setURIConverter(conv);
}
} catch (IOException e) {...}
if (conv != null) {
try {
conv.convert(bc, cc, cc.getBuffer().length -
cc.getEnd());
uri.setChars(cc.getBuffer(), cc.getStart(),
cc.getLength());
return;
} catch (IOException e) {...}
}
}
// Default encoding: fast conversion
byte[] bbuf = bc.getBuffer();
char[] cbuf = cc.getBuffer();
int start = bc.getStart();
for (int i = 0; i < length; i++) {
cbuf[i] = (char) (bbuf[i + start] & 0xff);
}
uri.setChars(cbuf, 0, length);
}
从上面的代码中可以知道对 URL 的 URI 部分进行解码的字符集是在 connector 的 中定义的,如果没有定义,那么将以默认编码 ISO-8859-1 解析。所以如果有中文 URL 时最好把 URIEncoding 设置成 UTF-8 编码。
QueryString 又如何解析? GET 方式 HTTP 请求的 QueryString 与 POST 方式 HTTP 请求的表单参数都是作为 Parameters 保存,都是通过 request.getParameter 获取参数值。对它们的解码是在 request.getParameter 方法第一次被调用时进行的。request.getParameter 方法被调用时将会调用 org.apache.catalina.connector.Request 的 parseParameters 方法。这个方法将会对 GET 和 POST 方式传递的参数进行解码,但是它们的解码字符集有可能不一样。POST 表单的解码将在后面介绍,QueryString 的解码字符集是在哪定义的呢?它本身是通过 HTTP 的 Header 传到服务端的,并且也在 URL 中,是否和 URI 的解码字符集一样呢?从前面浏览器对 PathInfo 和 QueryString 的编码采取不同的编码格式不同可以猜测到解码字符集肯定也不会是一致的。的确是这样 QueryString 的解码字符集要么是 Header 中 ContentType 中定义的 Charset 要么就是默认的 ISO-8859-1,要使用 ContentType 中定义的编码就要设置 connector 的 中的 useBodyEncodingForURI 设置为 true。这个配置项的名字有点让人产生混淆,它并不是对整个 URI 都采用 BodyEncoding 进行解码而仅仅是对 QueryString 使用 BodyEncoding 解码,这一点还要特别注意。
从上面的 URL 编码和解码过程来看,比较复杂,而且编码和解码并不是我们在应用程序中能完全控制的,所以在我们的应用程序中应该尽量避免在 URL 中使用非 ASCII 字符,不然很可能会碰到乱码问题,当然在我们的服务器端最好设置 中的 URIEncoding 和 useBodyEncodingForURI 两个参数。
HTTP Header 的编解码
当客户端发起一个 HTTP 请求除了上面的 URL 外还可能会在 Header 中传递其它参数如 Cookie、redirectPath 等,这些用户设置的值很可能也会存在编码问题,Tomcat 对它们又是怎么解码的呢?
对 Header 中的项进行解码也是在调用 request.getHeader 是进行的,如果请求的 Header 项没有解码则调用 MessageBytes 的 toString 方法,这个方法将从 byte 到 char 的转化使用的默认编码也是 ISO-8859-1,而我们也不能设置 Header 的其它解码格式,所以如果你设置 Header 中有非 ASCII 字符解码肯定会有乱码。
我们在添加 Header 时也是同样的道理,不要在 Header 中传递非 ASCII 字符,如果一定要传递的话,我们可以先将这些字符用 org.apache.catalina.util.URLEncoder 编码然后再添加到 Header 中,这样在浏览器到服务器的传递过程中就不会丢失信息了,如果我们要访问这些项时再按照相应的字符集解码就好了。
POST 表单的编解码
在前面提到了 POST 表单提交的参数的解码是在第一次调用 request.getParameter 发生的,POST 表单参数传递方式与 QueryString 不同,它是通过 HTTP 的 BODY 传递到服务端的。当我们在页面上点击 submit 按钮时浏览器首先将根据 ContentType 的 Charset 编码格式对表单填的参数进行编码然后提交到服务器端,在服务器端同样也是用 ContentType 中字符集进行解码。所以通过 POST 表单提交的参数一般不会出现问题,而且这个字符集编码是我们自己设置的,可以通过 request.setCharacterEncoding(charset) 来设置。
另外针对 multipart/form-data 类型的参数,也就是上传的文件编码同样也是使用 ContentType 定义的字符集编码,值得注意的地方是上传文件是用字节流的方式传输到服务器的本地临时目录,这个过程并没有涉及到字符编码,而真正编码是在将文件内容添加到 parameters 中,如果用这个编码不能编码时将会用默认编码 ISO-8859-1 来编码。
HTTP BODY 的编解码
当用户请求的资源已经成功获取后,这些内容将通过 Response 返回给客户端浏览器,这个过程先要经过编码再到浏览器进行解码。这个过程的编解码字符集可以通过 response.setCharacterEncoding 来设置,它将会覆盖 request.getCharacterEncoding 的值,并且通过 Header 的 Content-Type 返回客户端,浏览器接受到返回的 socket 流时将通过 Content-Type 的 charset 来解码,如果返回的 HTTP Header 中 Content-Type 没有设置 charset,那么浏览器将根据 Html 的 中的 charset 来解码。如果也没有定义的话,那么浏览器将使用默认的编码来解码。
其它需要编码的地方
除了 URL 和参数编码问题外,在服务端还有很多地方可能存在编码,如可能需要读取 xml、velocity 模版引擎、JSP 或者从数据库读取数据等。
xml 文件可以通过设置头来制定编码格式
<?xml version="1.0" encoding="UTF-8"?>
Velocity 模版设置编码格式:
services.VelocityService.input.encoding=UTF-8
JSP 设置编码格式:
<%@page contentType="text/html; charset=UTF-8"%>
访问数据库都是通过客户端 JDBC 驱动来完成,用 JDBC 来存取数据要和数据的内置编码保持一致,可以通过设置 JDBC URL 来制定如 MySQL:url="jdbc:mysql://localhost:3306/DB?useUnicode=true&characterEncoding=GBK"。
常见问题分析
在了解了 Java Web 中可能需要编码的地方后,下面看一下,当我们碰到一些乱码时,应该怎么处理这些问题?出现乱码问题唯一的原因都是在 char 到 byte 或 byte 到 char 转换中编码和解码的字符集不一致导致的,由于往往一次操作涉及到多次编解码,所以出现乱码时很难查找到底是哪个环节出现了问题,下面就几种常见的现象进行分析。
中文变成了看不懂的字符
例如,字符串“淘!我喜欢!”变成了“ì ? £ ?? ò ?2?? £ ?”编码过程如下图所示
![]()
字符串在解码时所用的字符集与编码字符集不一致导致汉字变成了看不懂的乱码,而且是一个汉字字符变成两个乱码字符。
一个汉字变成一个问号
例如,字符串“淘!我喜欢!”变成了“??????”编码过程如下图所示
![]()
将中文和中文符号经过不支持中文的 ISO-8859-1 编码后,所有字符变成了“?”,这是因为用 ISO-8859-1 进行编解码时遇到不在码值范围内的字符时统一用 3f 表示,这也就是通常所说的“黑洞”,所有 ISO-8859-1 不认识的字符都变成了“?”。
一个汉字变成两个问号
例如,字符串“淘!我喜欢!”变成了“????????????”编码过程如下图所示
![]()
这种情况比较复杂,中文经过多次编码,但是其中有一次编码或者解码不对仍然会出现中文字符变成“?”现象,出现这种情况要仔细查看中间的编码环节,找出出现编码错误的地方。
一种不正常的正确编码
还有一种情况是在我们通过 request.getParameter 获取参数值时,当我们直接调用
String value = request.getParameter(name);
会出现乱码,但是如果用下面的方式
String value = String(request.getParameter(name).getBytes("
ISO-8859-1"), "GBK");
解析时取得的 value 会是正确的汉字字符,这种情况是怎么造成的呢?
看下如所示:
![]()
这种情况是这样的,ISO-8859-1 字符集的编码范围是 0000-00FF,正好和一个字节的编码范围相对应。这种特性保证了使用 ISO-8859-1 进行编码和解码可以保持编码数值“不变”。虽然中文字符在经过网络传输时,被错误地“拆”成了两个欧洲字符,但由于输出时也是用 ISO-8859-1,结果被“拆”开的中文字的两半又被合并在一起,从而又刚好组成了一个正确的汉字。虽然最终能取得正确的汉字,但是还是不建议用这种不正常的方式取得参数值,因为这中间增加了一次额外的编码与解码,这种情况出现乱码时因为 Tomcat 的配置文件中 useBodyEncodingForURI 配置项没有设置为”true”,从而造成第一次解析式用 ISO-8859-1 来解析才造成乱码的。
总结
本文首先总结了几种常见编码格式的区别,然后介绍了支持中文的几种编码格式,并比较了它们的使用场景。接着介绍了 Java 那些地方会涉及到编码问题,已经 Java 中如何对编码的支持。并以网络 I/O 为例重点介绍了 HTTP 请求中的存在编码的地方,以及 Tomcat 对 HTTP 协议的解析,最后分析了我们平常遇到的乱码问题出现的原因。
综上所述,要解决中文问题,首先要搞清楚哪些地方会引起字符到字节的编码以及字节到字符的解码,最常见的地方就是读取会存储数据到磁盘,或者数据要经过网络传输。然后针对这些地方搞清楚操作这些数据的框架的或系统是如何控制编码的,正确设置编码格式,避免使用软件默认的或者是操作系统平台默认的编码格式。
参考资料
学习
Unicode 编码规范,详细描述了 Unicode 如何编码。
ISO-8859-1 编码,详细介绍了 ISO-8859-1 的一些细节。
RFC3986 规范,详细描述了 URL 编码规范
HTTP 协议,W3C 关于 HTTP 协议的详细描述。
查看文章 《 Tomcat 系统架构与设计模式》(developerWorks,2010 年 5 月):了解 Tomcat 中容器的体系结构,基本的工作原理,以及 Tomcat 中使用的经典的设计模式介绍。
Servlet 工作原理解析,(developerWorks,2011 年 2 月):以 Tomcat 为例了解 Servlet 容器是如何工作的?一个 Web 工程在 Servlet 容器中是如何启动的? Servlet 容器如何解析你在 web.xml 中定义的 Servlet ?用户的请求是如何被分配给指定的 Servlet 的? Servlet 容器如何管理 Servlet 生命周期?你还将了解到最新的 Servlet 的 API 的类层次结构,以及 Servlet 中一些难点问题的分析。
developerWorks Java 技术专区:这里有数百篇关于 Java 编程各个方面的文章。
来源: [http://www.uml.org.cn/j2ee/201107271.asp](http://www.uml.org.cn/j2ee/201107271.asp)
线性表分析及Java实现
线性表分析及Java实现
文章分类**:综合技术**
数据结构中的线性表,对应着Collection中的List接口。
在本节中,我们将做以下三件事
第一。我们先来看看线性表的特征
第二,自己用JAVA实现List
第三,对比的线性表、链式表性能,以及自己的List性能与JDKList性能对比
** ****线性表特征:**** **
第一,一个特定的线性表,应该是用来存放特定的某一个类型的元素的(元素的“同一性”)
第二, 除第一个元素外,其他每一个元素有且仅有一个直接前驱;除最后一个元素外,其他每一个元素有且仅有一个 直接后继(元素的“序偶性”)
第二, 元素在线性表中的“下标”唯一地确定该元素在表中的相对位置(元素的“索引性”)
又,一.线性表只是数据的一种逻辑结构,其具体存储结构可以为顺序存储结构和链式储存结构来完成,对应可以得到顺序表和链表,
二.对线性表的入表和出表顺序做一定的限定,可以得到特殊的线性表,栈(FILO)和队列(FIFO)
**自己实现线性表之顺序表**
思路:
1. 顺序表因为采用顺序存储形式,所以内部使用数组来存储数据
2.因为存储的具体对象类型不一定,所以采用泛型操作
3.数组操作优点:1.通过指针快速定位到下表,查询快速
缺点:1.数组声明时即需要确定数组大小。当操作中超过容量时,则需要重新声明数组,并且复制当前所有数据
2.当需要在中间进行插入或者删除时,则需要移动大量元素(size-index个)
具体实现代码如下
Java**代码 [![收藏代码]()**](""收藏这段代码" ") **
**
///
/* 自己用数组实现的线性表
/*/
public class ArrayList {
Object[] data = null;// 用来保存此队列中内容的数组
int current;// 保存当前为第几个元素的指标
int capacity;// 表示数组大小的指标
///
/* 如果初始化时,未声明大小,则默认为10
/*/
public ArrayList() {
this(10);
}
///
/* 初始化线性表,并且声明保存内容的数组大小
/* @param initalSize
/*/
public ArrayList(int initalSize) {
if (initalSize < 0) {
throw new RuntimeException("数组大小错误:" + initalSize);
} else {
this.data = new Object[initalSize];
this.current = 0;
capacity = initalSize;
}
}
///
/* 添加元素的方法 添加前,先确认是否已经满了
/* @param e
/* @return
/*/
public boolean add(E e) {
ensureCapacity(current);// 确认容量
this.data[current] = e;
current++;
return true;
}
///
/* 确认系统当前容量是否满足需要,如果满足,则不执行操作 如果不满足,增加容量
/* @param cur 当前个数
/*/
private void ensureCapacity(int cur) {
if (cur == capacity) {
// 如果达到容量极限,增加10的容量,复制当前数组
this.capacity = this.capacity + 10;
Object[] newdata = new Object[capacity];
for (int i = 0; i < cur; i++) {
newdata[i] = this.data[i];
}
this.data = newdata;
}
}
///
/* 得到指定下标的数据
/* @param index
/* @return
/*/
public E get(int index) {
validateIndex(index);
return (E) this.data[index];
}
///
/* 返回当前队列大小
/* @return
/*/
public int size() {
return this.current;
}
///
/* 更改指定下标元素的数据为e
/* @param index
/* @param e
/* @return
/*/
public boolean set(int index, E e) {
validateIndex(index);
this.data[index] = e;
return true;
}
///
/* 验证当前下标是否合法,如果不合法,抛出运行时异常
/* @param index 下标
/*/
private void validateIndex(int index) {
if (index < 0 || index > current) {
throw new RuntimeException("数组index错误:" + index);
}
}
///
/* 在指定下标位置处插入数据e
/* @param index 下标
/* @param e 需要插入的数据
/* @return
/*/
public boolean insert(int index, E e) {
validateIndex(index);
Object[] tem = new Object[capacity];// 用一个临时数组作为备份
//开始备份数组
for (int i = 0; i < current; i++) {
if (i < index) {
tem[i] = this.data[i];
}else if(i==index){
tem[i]=e;
}else if(i>index){
tem[i]=this.data[i-1];
}
}
this.data=tem;
return true;
}
///
/ 删除指定下标出的数据
/ @param index
/ @return
//
public boolean delete(int index){
validateIndex(index);
Object[] tem = new Object[capacity];// 用一个临时数组作为备份
//开始备份数组
for (int i = 0; i < current; i++) {
if (i < index) {
tem[i] = this.data[i];
}else if(i==index){
tem[i]=this.data[i+1];
}else if(i>index){
tem[i]=this.data[i+1];
}
}
this.data=tem;
return true;
}
}
**自己实现线性表之链表**
思路:1.链表采用链式存储结构,在内部只需要将一个一个结点链接起来。(每个结点中有关于此结点下一个结点的引用)
链表操作优点:1.,因为每个结点记录下个结点的引用,则在进行插入和删除操作时,只需要改变对应下标下结点的引用即可
缺点:1.要得到某个下标的数据,不能通过下标直接得到,需要遍历整个链表。
实现代码如下
Java**代码 [**
///
/* 自己用链式存储实现的线性表
/*/
public class LinkedList {
private Node header = null;// 头结点
int size = 0;// 表示数组大小的指标
public LinkedList() {
this.header = new Node();
}
public boolean add(E e) {
if (size == 0) {
header.e = e;
} else {
// 根据需要添加的内容,封装为结点
Node newNode = new Node(e);
// 得到当前最后一个结点
Node last = getNode(size-1);
// 在最后一个结点后加上新结点
last.addNext(newNode);
}
size++;// 当前大小自增加1
return true;
}
public boolean insert(int index, E e) {
Node newNode = new Node(e);
// 得到第N个结点
Node cNode = getNode(index);
newNode.next = cNode.next;
cNode.next = newNode;
size++;
return true;
}
///
/* 遍历当前链表,取得当前索引对应的元素
/*
/* @return
/*/
private Node getNode(int index) {
// 先判断索引正确性
if (index > size || index < 0) {
throw new RuntimeException("索引值有错:" + index);
}
Node tem = new Node();
tem = header;
int count = 0;
while (count != index) {
tem = tem.next;
count++;
}
return tem;
}
///
/* 根据索引,取得该索引下的数据
/*
/* @param index
/* @return
/*/
public E get(int index) {
// 先判断索引正确性
if (index >= size || index < 0) {
throw new RuntimeException("索引值有错:" + index);
}
Node tem = new Node();
tem = header;
int count = 0;
while (count != index) {
tem = tem.next;
count++;
}
E e = tem.e;
return e;
}
public int size() {
return size;
}
///
/* 设置第N个结点的值
/*
/* @param x
/* @param e
/* @return
/*/
public boolean set(int index, E e) {
// 先判断索引正确性
if (index > size || index < 0) {
throw new RuntimeException("索引值有错:" + index);
}
Node newNode = new Node(e);
// 得到第x个结点
Node cNode = getNode(index);
cNode.e = e;
return true;
}
///
/* 用来存放数据的结点型内部类
/*/
class Node {
private E e;// 结点中存放的数据
Node() {
}
Node(E e) {
this.e = e;
}
Node next;// 用来指向该结点的下一个结点
// 在此结点后加一个结点
void addNext(Node node) {
next = node;
}
}
}
自己实现线性表之栈
栈是限定仅允许在表的同一端(通常为“表尾”)进行插入或删除操作的线性表。
允许插入和删除的一端称为栈顶(top),另一端称为栈底(base)
特点:后进先出 (LIFO)或,先进后出(FILO)
因为栈是限定线的线性表,所以,我们可以调用前面两种线性表,只需要对出栈和入栈操作进行设定即可
具体实现代码
Java**代码 [**
///
/* 自己用数组实现的栈
/*/
public class ArrayStack {
private ArrayList list=new ArrayList();//用来保存数据线性表
private int size;//表示当前栈元素个数
///
/* 入栈操作
/* @param e
/*/
public void push(E e){
list.add(e);
size++;
}
///
/* 出栈操作
/* @return
/*/
public E pop(){
E e= list.get(size-1);
size--;
return e;
}
}
至于用链表实现栈,则只需要把保存数据的顺序表改成链表即可,此处就不给出代码了
自己实现线性表之队列
与栈类似
队列是只允许在表的一端进行插入,而在另一端删除元素的线性表。
在队列中,允许插入的一端叫队尾(rear),允许删除的一端称为队头(front)。
特点:先进先出 (FIFO)、后进后出 (LILO)
同理,我们也可以调用前面两种线性表,只需要对队列的入队和出队方式进行处理即可
Java**代码 [**
package cn.javamzd.collection.List;
///
/* 用数组实现的队列
/*/
public class ArrayQueue {
private ArrayList list = new ArrayList();// 用来保存数据的队列
private int size;// 表示当前栈元素个数
///
/* 入队
/* @param e
/*/
public void EnQueue(E e) {
list.add(e);
size++;
}
///
/* 出队
/* @return
/*/
public E DeQueue() {
if (size > 0) {
E e = list.get(0);
list.delete(0);
return e;
}else{
throw new RuntimeException("已经到达队列顶部");
}
}
}
对比线性表和链式表
前面已经说过顺序表和链式表各自的特点,这里在重申一遍
数组操作优点:1.通过指针快速定位到下标,查询快速
缺点:1.数组声明时即需要确定数组大小。当操作中超过容量时,则需要重新声明数组,并且复制当前所有数据
2.当需要在中间进行插入或者删除时,则需要移动大量元素(size-index个)
链表操作优点:1.,因为每个结点记录下个结点的引用,则在进行插入和删除操作时,只需要改变对应下标下结点的引用即可
缺点:1.要得到某个下标的数据,不能通过下标直接得到,需要遍历整个链表。
现在,我们通过进行增删改查操作来感受一次其效率的差异
**思路**:通过两个表,各进行大数据量操作(2W)条数据的操作,记录操作前系统时间,操作后系统时间,得出操作时间
实现代码如下
Java**代码 [**
package cn.javamzd.collection.List;
public class Test {
///
/* @param args
/*/
public static void main(String[] args) {
//测试自己实现的ArrayList类和Linkedlist类添加20000个数据所需要的时间
ArrayList al = new ArrayList();
LinkedList ll = new LinkedList();
Long aBeginTime=System.currentTimeMillis();//记录BeginTime
for(int i=0;i<30000;i++){
al.add("now"+i);
}
Long aEndTime=System.currentTimeMillis();//记录EndTime
System.out.println("arrylist add time--->"+(aEndTime-aBeginTime));
Long lBeginTime=System.currentTimeMillis();//记录BeginTime
for(int i=0;i<30000;i++){
ll.add("now"+i);
}
Long lEndTime=System.currentTimeMillis();//记录EndTime
System.out.println("linkedList add time---->"+(lEndTime-lBeginTime));
//测试JDK提供的ArrayList类和LinkedList类添加20000个数据所需要的世界
java.util.ArrayList sal=new java.util.ArrayList();
java.util.LinkedList sll=new java.util.LinkedList();
Long saBeginTime=System.currentTimeMillis();//记录BeginTime
for(int i=0;i<30000;i++){
sal.add("now"+i);
}
Long saEndTime=System.currentTimeMillis();//记录EndTime
System.out.println("JDK arrylist add time--->"+(saEndTime-saBeginTime));
Long slBeginTime=System.currentTimeMillis();//记录BeginTime
for(int i=0;i<30000;i++){
sll.add("now"+i);
}
Long slEndTime=System.currentTimeMillis();//记录EndTime
System.out.println("JDK linkedList add time---->"+(slEndTime-slBeginTime));
}
}
得到测试结果如下:
arrylist add time--->446
linkedList add time---->9767
JDK arrylist add time--->13
JDK linkedList add time---->12
由以上数据,我们可知:
1.JDK**中的ArrayList何LinkedList在添加数据时的性能,其实几乎是没有差异的**
2.我们自己写的List的性能和JDK提供的List的性能还是存在巨大差异的
3.我们使用链表添加操作,花费的时间是巨大的,比ArrayList都大几十倍
第三条显然是跟我们最初的设计不相符的,按照我们最初的设想,链表的添加应该比顺序表更省时
查看我们写的源码,可以发现:
我们每次添加一个数据时,都需要遍历整个表,得到表尾,再在表尾添加,这是很不科学的
** ****现改进如下**:设立一个Node<E>类的成员变量end来指示表尾,这样每次添加时,就不需要再重新遍历得到表尾
改进后add()方法如下
Java**代码 [**
public boolean add(E e) {
if (size == 0) {
header.e = e;
} else {
// 根据需要添加的内容,封装为结点
Node newNode = new Node(e);
//在表尾添加元素
last.addNext(newNode);
//将表尾指向当前最后一个元素
last = newNode;
}
size++;// 当前大小自增加1
return true;
}
ArrayList添加的效率和JDK中对比起来也太低
分析原因为:
每次扩大容量时,扩大量太小,需要进行的复制操作太多
现在改进如下:
每次扩大,则扩大容量为当前的三倍,此改进仅需要更改ensureCapacity()方法中的一行代码,此处就不列出了。
改进后,再次运行添加元素测试代码,结果如下:
arrylist add time--->16
linkedList add time---->8
JDK arrylist add time--->7
JDK linkedList add time---->7
虽然还有改进的空间,但是显然,我们的效果已经大幅度改进了,而且也比较接近JDK了
接下来测试插入操作的效率
我们只需要将测试代码中的添加方法(add())改成插入方法(insert(int index,E e)),为了使插入次数尽可能多,我们把index都设置为0
测试结果如下:
arrylist inset time--->17
linkedList inset time---->13
JDK arrylist inset time--->503
JDK linkedList inset time---->11
多次测试,发现我们写的**ArrayList在插入方法的效率都已经超过JDK了,而且也接近LinkedLst**了。撒花!!!
接下来测试删除、得到下标等等操作就不一一列出来了(只需要改变每次调用的方法即可)
恩,本来想今晚把所有的集合框架实现都写一下的
但是不知不觉这都又2点了
明早还得去蓝杰上课
果断先睡吧
敬请大家期待我明日大作------------静态/动态查找表的实现,动态查找表查找/加入算法的JAVA实现,Hash表的实现
good night
url: http://java-mzd.iteye.com/blog/826059