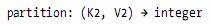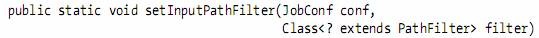Notes for Hadoop the definitive guide
1. Introduction to HDFS
1.1. HDFS Concepts
1.1.1. Blocks
l HDFS too has the concept of a block, but it is a much larger unit 64 MB by default.
l Like in a filesystem for a single disk, files in HDFS are broken into block-sized chunks, which are stored as independent units.
l Unlike a filesystem for a single disk, a file in HDFS that is smaller than a single block does not occupy a full block’s worth of underlying storage.
1.1.2. Namenodes and Datanodes
l The namenode manages the filesystem namespace.
n It maintains the filesystem tree and the metadata for all the files and directories in the tree.
n This information is stored persistently on the local disk in the form of two files: the namespace image and the edit log.
n The namenode also knows the datanodes on which all the blocks for a given file are located, however, it does not store block locations persistently, since this information is reconstructed from datanodes when the system starts.
l Datanodes are the work horses of the filesystem.
n They store and retrieve blocks when they are told to (by clients or the namenode)
n They report back to the namenode periodically with lists of blocks that they are storing.
l secondary namenode
n It does not act as a namenode.
n Its main role is to periodically merge the namespace image with the edit log to prevent the edit log from becoming too large.
n It keeps a copy of the merged name space image, which can be used in the event of the namenode failing.
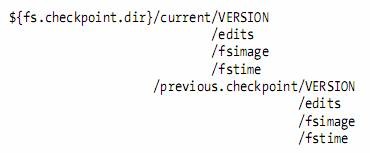
Namenode directory structure

l The VERSION file is a Java properties file that contains information about the version of HDFS that is running
n The layoutVersion is a negative integer that defines the version of HDFS’s persistent data structures.
n The namespaceID is a unique identifier for the filesystem, which is created when the filesystem is first formatted.
n The cTime property marks the creation time of the namenode’s storage.
n The storageType indicates that this storage directory contains data structures for a namenode.

The filesystem image and edit log
l When a filesystem client performs a write operation, it is first recorded in the edit log.
l The namenode also has an in-memory representation of the filesystem metadata, which it updates after the edit log has been modified.
l The edit log is flushed and synced after every write before a success code is returned to the client.
l The fsimage file is a persistent checkpoint of the filesystem metadata. it is not updated for every filesystem write operation.
l If the namenode fails, then the latest state of its metadata can be reconstructed by loading the fsimage from disk into memory, then applying each of the operations in the edit log.
l This is precisely what the namenode does when it starts up.
l The fsimage file contains a serialized form of all the directory and file inodes in the filesystem.
l The secondary namenode is to produce checkpoints of the primary’s in-memory filesystem metadata.
l The checkpointing process proceeds as follows :
n The secondary asks the primary to roll its edits file, so new edits go to a new file.
n The secondary retrieves fsimage and edits from the primary (using HTTP GET).
n The secondary loads fsimage into memory, applies each operation from edits, then creates a new consolidated fsimage file.
n The secondary sends the new fsimage back to the primary (using HTTP POST).
n The primary replaces the old fsimage with the new one from the secondary, and the old edits file with the new one it started in step 1. It also updates the fstime file to record the time that the checkpoint was taken.
n At the end of the process, the primary has an up-to-date fsimage file, and a shorter edits file.

Secondary namenode directory structure

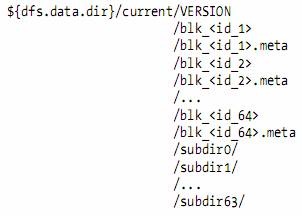
Datanode directory structure

l A datanode’s VERSION file

l The other files in the datanode’s current storage directory are the files with the blk_ prefix.
n There are two types: the HDFS blocks themselves (which just consist of the file’s raw bytes) and the metadata for a block (with a .meta suffix).
n A block file just consists of the raw bytes of a portion of the file being stored;
n the metadata file is made up of a header with version and type information, followed by a series of checksums for sections of the block.
l When the number of blocks in a directory grows to a certain size, the datanode creates a new subdirectory in which to place new blocks and their accompanying metadata.
1.2. Data Flow
1.2.1. Anatomy of a File Read

l The client opens the file it wishes to read by calling open() on the FileSystem object (step 1).
l DistributedFileSystem calls the namenode, using RPC, to determine the locations of the blocks for the first few blocks in the file (step 2).
l For each block, the namenode returns the addresses of the datanodes that have a copy of that block.
l The datanodes are sorted according to their proximity to the client.
l The DistributedFileSystem returns a FSDataInputStream to the client for it to read data from.
l The client then calls read() on the stream (step 3).
l DFSInputStream connects to the first (closest) datanode for the first block in the file.
l Data is streamed from the datanode back to the client (step 4).
l When the end of the block is reached, DFSInputStream will close the connection to the datanode, then find the best datanode for the next block (step 5).
l When the client has finished reading, it calls close() on the FSDataInputStream (step 6).
l During reading, if the client encounters an error while communicating with a datanode, then it will try the next closest one for that block.
l It will also remember datanodes that have failed so that it doesn’t needlessly retry them for later blocks.
l The client also verifies checksums for the data transferred to it from the datanode. If a corrupted block is found, it is reported to the namenode.
1.2.2. Anatomy of a File Write

l The client creates the file by calling create() (step 1).
l DistributedFileSystem makes an RPC call to the namenode to create a new file in the filesystem’s namespace, with no blocks associated with it (step 2).
l The namenode performs various checks to make sure the file doesn’t already exist, and that the client has the right permissions to create the file. If these checks pass, the namenode makes a record of the new file; otherwise, file creation fails and the client is thrown an IOException.
l The DistributedFileSystem returns a FSDataOutputStream for the client to start writing data to.
l As the client writes data (step 3), DFSOutputStream splits it into packets, which it writes to an internal queue, called the data queue.
l The data queue is consumed by the Data Streamer, whose responsibility it is to ask the namenode to allocate new blocks by picking a list of suitable datanodes to store the replicas. The list of datanodes forms apipeline.
l The DataStreamer streams the packets to the first datanode in the pipeline, which stores the packet and forwards it to the second datanode in the pipeline. Similarly, the second datanode stores the packet and forwards it to the third (and last) datanode in the pipe line (step 4).
l DFSOutputStream also maintains an internal queue of packets that are waiting to be acknowledged by datanodes, called the ack queue. A packet is removed from the ack queue only when it has been acknowledged by all the datanodes in the pipeline (step 5).
l If a datanode fails while data is being written to it,
n First the pipeline is closed, and any packets in the ack queue are added to the front of the data queue.
n The current block on the good datanodes is given a new identity by the namenode, so that the partial block on the failed datanode will be deleted if the failed data node recovers later on.
n The failed datanode is removed from the pipeline and the remainder of the block’s data is written to the two good datanodes in the pipeline.
n The namenode notices that the block is under-replicated, and it arranges for a further replica to be created on another node.
l When the client has finished writing data it calls close() on the stream (step 6). This action flushes all the remaining packets to the datanode pipeline and waits for acknowledgments before contacting the namenode to signal that the file is complete (step7).
2. Meet Map/Reduce
l MapReduce has two phases: the map phase and the reduce phase.
l Each phase has key-value pairs as input and output (the types can be specified).
n The input key-value types of the map phase is determined by the input format
n The output key-value types of the map phase should match the input key value types of the reduce phase
n The output key-value types of the reduce phase can be set in the JobConf interface.
l The programmer specifies two functions: the map function and the reduce function.
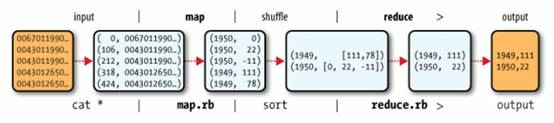
2.1. MapReduce logical data flow

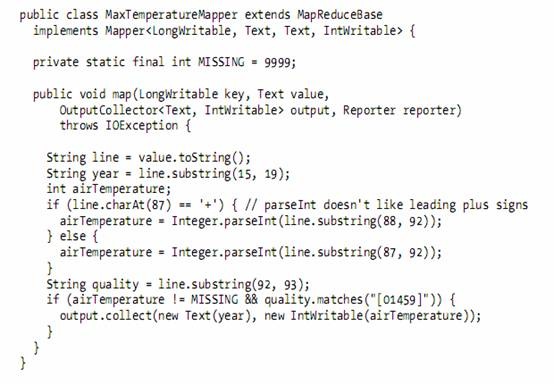
2.2. MapReduce Code
2.2.1. The map function is represented by an implementation of the Mapper interface, which declares a map() method.

2.2.2. The reduce function is defined using a Reducer
l The input types of the reduce function must match the output type of the map function.

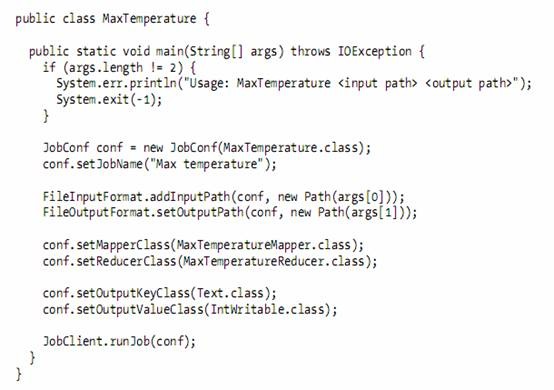
2.2.3. The code runs the MapReduce job
l An input path is specified by calling the static addInputPath() method on FileInputFormat
n It can be a single file, a directory, or a file pattern.
n addInputPath() can be called more than once to use input from multiple paths.
l The output path is specified by the static setOutputPath() method on FileOutputFormat.
n It specifies a directory where the output files from the reducer functions are written.
n The directory shouldn’t exist before running the job
l The map and reduce types can be specified via the setMapperClass() and setReducerClass() methods.
l The setOutputKeyClass() and setOutputValueClass() methods control the output types for the map and the reduce functions, which are often the same.
n If they are different, then the map output types can be set using the methods setMapOutputKeyClass() and setMapOutputValueClass().
l The input types are controlled via the input format, which we have not explicitly set since we are using the default TextInputFormat.

2.3. Scaling Out
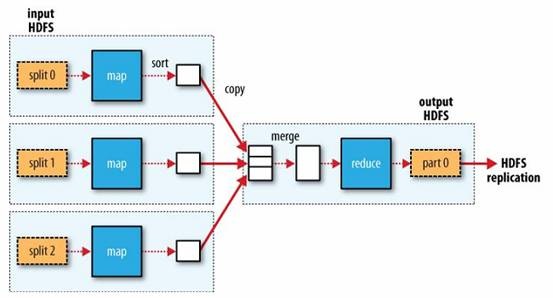
2.3.1. MapReduce data flow with a single reduce task
l A MapReduce job is a unit of work that the client wants to be performed: it consists of the input data, the MapReduce program, and configuration information.
l Hadoop runs the job by dividing it into tasks, of which there are two types: map tasks and reduce tasks.
l There are two types of nodes that control the job execution process: a jobtracker and a number of tasktrackers.
n The jobtracker coordinates all the jobs run on the system by scheduling tasks to run on tasktrackers.
n Tasktrackers run tasks and send progress reports to the jobtracker, which keeps a record of the overall progress of each job.
n If a tasks fails, the jobtracker can reschedule it on a different tasktracker.
l Hadoop divides the input to a MapReduce job into fixed-size input splits.
l Hadoop creates one map task for each split, which runs the user defined map function for each record in the split.
l Hadoop does its best to run the map task on a node where the input data resides in HDFS.
n This is called the data locality optimization.
n This is why the optimal split size is the same as the block size: it is the largest size of input that can be guaranteed to be stored on a single node.
l Reduce tasks don’t have the advantage of data locality
n The input to a single reduce task is normally the output from all mappers.
n The output of the reduce is normally stored in HDFS for reliability.

2.3.2. MapReduce data flow with multiple reduce tasks
The number of reduce tasks is not governed by the size of the input, but is specified independently.
l When there are multiple reducers, the map tasks partition their output, each creating one partition for each reduce task.
l There can be many keys (and their associated values) in each partition, but the records for every key are all in a single partition.
l The partitioning can be controlled by a user-defined partitioning function
n Normally the default partitioner which buckets keys using a hash function.
n conf.setPartitionerClass(HashPartitioner.class);
n conf.setNumReduceTasks(1);
l The data flow between map and reduce tasks is “the shuffle,” as each reduce task is fed by many map tasks.

l It’s also possible to have zero reduce tasks. This can be appropriate when you don’t need the shuffle since the processing can be carried out entirely in parallel
3.1. MapReduce Types
l The map and reduce functions in Hadoop MapReduce have the following general form:


l The partition function operates on the intermediate key and value types (K2 and V2), and returns the partition index.


3.1.1. Configuration of MapReduce types

l Input types are set by the input format.
n For instance, a TextInputFormat generates keys of type LongWritable and values of type Text.
l A minimal MapReduce driver, with the defaults explicitly set

l The default input format is TextInputFormat, which produces keys of type LongWritable (the offset of the beginning of the line in the file) and values of type Text (the line of text).
l The setNumMapTasks() call does not necessarily set the number of map tasks to one
n The actual number of map tasks depends on the size of the input
l The default mapper is IdentityMapper

l Map tasks are run by MapRunner, the default implementation of MapRunnable that calls the Mapper’s map() method sequentially with each record.
l The default partitioner is HashPartitioner, which hashes a record’s key to determine which partition the record belongs in.
n Each partition is processed by a reduce task, so the number of partitions is equal to the number of reduce tasks for the job

l The default reducer is IdentityReducer

l Records are sorted by the MapReduce system before being presented to the reducer.
l The default output format is TextOutputFormat, which writes out records, one per line, by converting keys and values to strings and separating them with a tab character.
l An input split is a chunk of the input that is processed by a single map.
l Each split is divided into records, and the map processes each record—a key-value pair—in turn.

l An InputSplit has a length in bytes, and a set of storage locations, which are just hostname strings.
l A split doesn’t contain the input data; it is just a reference to the data.
l The storage locations are used by the MapReduce system to place map tasks as close to the split’s data as possible
l The size is used to order the splits so that the largest get processed first
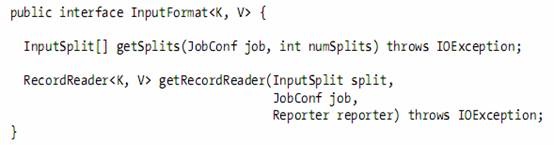
l An InputFormat is responsible for creating the input splits, and dividing them into records.

l The JobClient calls the getSplits() method, passing the desired number of map tasks as the numSplits argument.
l Having calculated the splits, the client sends them to the jobtracker, which uses their storage locations to schedule map tasks to process them on the tasktrackers.
l On a tasktracker, the map task passes the split to the getRecordReader() method on InputFormat to obtain a RecordReader for that split.
l A RecordReader is little more than an iterator over records, and the map task uses one to generate record key-value pairs, which it passes to the map function.

l The same key and value objects are used on each invocation of the map() method—only their contents are changed. If you need to change the value out of map, make a copy of the object you want to hold on to.
l FileInputFormat is the base class for all implementations of InputFormat that use files as their data source.
l It provides two things: a place to define which files are included as the input to a job, and an implementation for generating splits for the input files.

l FileInputFormat input paths may represent a file, a directory, or, by using a glob, a collection of files and directories.

l To exclude certain files from the input, you can set a filter using the setInputPathFilter() method on FileInputFormat

l FileInputFormat splits only large files. Here “large” means larger than an HDFS block.
l Properties for controlling split size
n The minimum split size is usually 1 byte, by setting this to a value larger than the block size, they can force splits to be larger than a block.
n The maximum split size defaults to the maximum value that can be represented by a Java long type. It has an effect only when it is less than the block size, forcing splits to be smaller than a block.
l Hadoop works better with a small number of large files than a large number of small files.
l Where FileInputFormat creates a split per file, CombineFileInputFormat packs many files into each split so that each mapper has more to process.
l One technique for avoiding the many small files case is to merge small files into larger files by using a SequenceFile: the keys can act as filenames and the values as file contents.
3.2.3. Text Input
l TextInputFormat is the default InputFormat.
n Each record is a line of input.
n The key, a LongWritable, is the byte offset within the file of the beginning of the line.
n The value is the contents of the line, excluding any line terminators, and is packaged as a Text object.
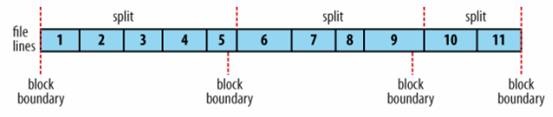
l The logical records that FileInputFormats define do not usually fit neatly into HDFS blocks.
l A single file is broken into lines, and the line boundaries do not correspond with the HDFS block boundaries.
l Splits honor logical record boundaries
n The first split contains line 5, even though it spans the first and second block.
n The second split starts at line 6.
l Data-local maps will perform some remote reads.

KeyValueTextInputFormat
l It is common for each line in a file to be a key-value pair, separated by a delimiter such as a tab character.
l You can specify the separator via the key.value.separator.in.input.line property.
l If you want your mappers to receive a fixed number of lines of input, then NLineInputFormat is the InputFormat to use.
l Like TextInputFormat, the keys are the byte offsets within the file and the values are the lines themselves.
l N refers to the number of lines of input that each mapper receives.
l Hadoop’s sequence file format stores sequences of binary key-value pairs.
l To use data from sequence files as the input to MapReduce, you use SequenceFileInputFormat.
l The keys and values are determined by the sequence file, and you need to make sure that your map input types correspond.
l For example, if your sequence file has IntWritable keys and Text values, then the map signature would be Mapper.
SequenceFileAsTextInputFormat
l SequenceFileAsTextInputFormat is a variant of SequenceFileInputFormat that converts the sequence file’s keys and values to Text objects.
l SequenceFileAsBinaryInputFormat is a variant of SequenceFileInputFormat that retrieves the sequence file’s keys and values as opaque binary objects.
l They are encapsulated as BytesWritable objects
SequenceFile
l Writing a SequenceFile
n To create a SequenceFile, use one of its createWriter() static methods, which returns a SequenceFile.Writer instance.
n specify a stream to write to (either a FSDataOutputStream or a FileSystem and Path pairing), a Configuration object, and the key and value types.
n Once you have a SequenceFile.Writer, you then write key-value pairs, using the append() method.
n Then when you’ve finished you call the close() method

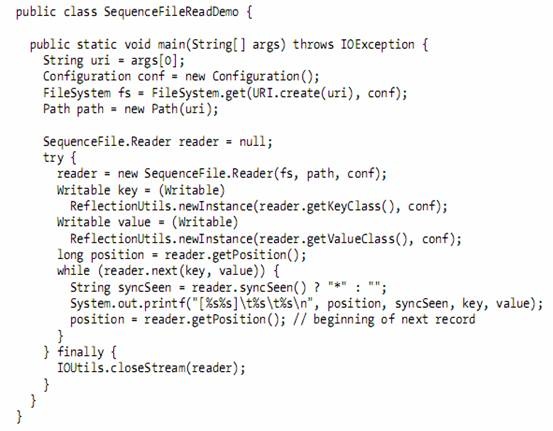
l Reading a SequenceFile
n Reading sequence files from beginning to end is a matter of creating an instance of SequenceFile.Reader, and iterating over records by repeatedly invoking one of the next() methods.

l The SequenceFile Format
n A sequence file consists of a header followed by one or more records.
n The first three bytes of a sequence file are the bytes SEQ, which acts a magic number, followed by a single byte representing the version number.
n The header contains other fields including the names of the key and value classes, compression details, user-defined metadata, and the sync marker.
n The sync marker is used to allow a reader to synchronize to a record boundary from any position in the file.

l The MultipleInputs class allows you to specify the InputFormat and Mapper to use on a per-path basis.

3.3.1. Text Output
l The default output format, TextOutputFormat, writes records as lines of text.
l Its keys and values may be of any type, since TextOutputFormat turns them to strings by calling toString() on them.
l Each key-value pair is separated by a tab character, although that may be changed using the mapred.textoutputformat.separator property.
3.3.2. Binary Output
l SequenceFileOutputFormat
l SequenceFileAsBinaryOutputFormat
l MapFileOutputFormat
Writing a MapFile
l You create an instance of MapFile.Writer, then call the append() method to add entries in order.
l Keys must be instances of WritableComparable, and values must be Writable

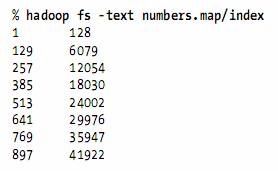
l If we look at the MapFile, we see it’s actually a directory containing two files called data and index:

l Both files are SequenceFiles. The data file contains all of the entries, in order:

l The index file contains a fraction of the keys, and contains a mapping from the key to that key’s offset in the data file:

Reading a MapFile
l you create a MapFile.Reader, then call the next() method until it returns false
3.3.3. Multiple Outputs
l MultipleOutputFormat allows you to write data to multiple files whose names are derived from the output keys and values.
n conf.setOutputFormat(StationNameMultipleTextOutputFormat.class);

MultipleOutputs
l MultipleOutputs can emit different types for each output.

4. Developing a MapReduce Application
4.1. The Configuration API
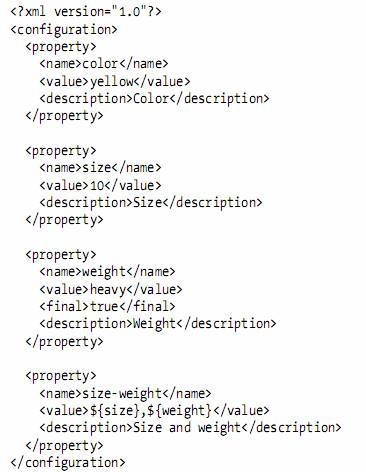
l An instance of the Configuration class (found in the org.apache.hadoop.conf package) represents a collection of configuration properties and their values.
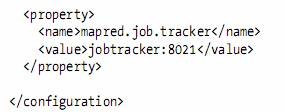
l Configurations read their properties from resources—XML files

l we can access its properties using a piece of code like this:

4.2. Configuring the Development Environment
4.2.1. Managing Configuration
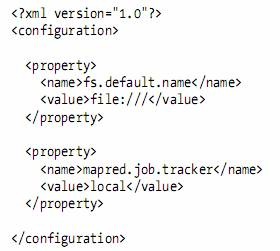
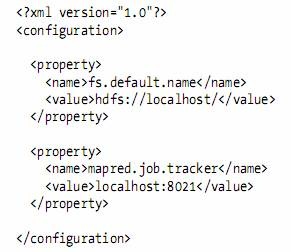
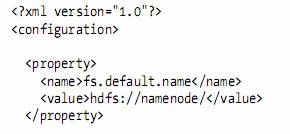
l When developing Hadoop applications, it is common to switch between running the application locally and running it on a cluster.
l hadoop-local.xml

l hadoop-localhost.xml

l hadoop-cluster.xml


l With this setup, it is easy to use any configuration with the -conf command-line switch.
l For example, the following command shows a directory listing on the HDFS server running in pseudo-distributed mode on localhost:



5. How MapReduce Works
5.1. Anatomy of a MapReduce Job Run
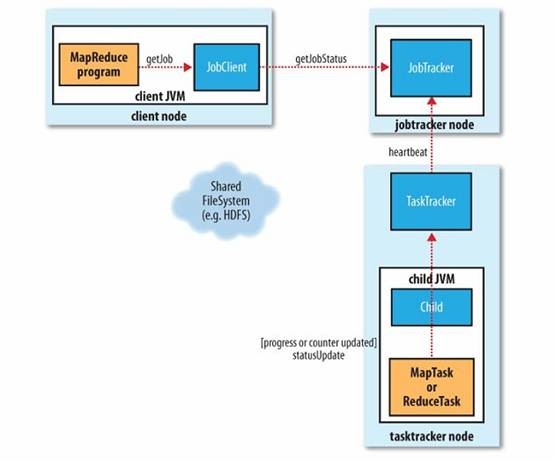
l There are four independent entities:
n The client, which submits the MapReduce job.
n The jobtracker, which coordinates the job run. The jobtracker is a Java application whose main class is JobTracker.
n The tasktrackers, which run the tasks that the job has been split into. Tasktrackers are Java applications whose main class is TaskTracker.
n The distributed filesystem, which is used for sharing job files between the other entities.

5.1.1. Job Submission
l The runJob() method on JobClient creates a new JobClient instance and calls submitJob() on it.
l Having submitted the job, runJob() polls the job’s progress once a second, and reports the progress to the console if it has changed since the last report.
l When the job is complete, if it was successful, the job counters are displayed. Otherwise, the error that caused the job to fail is logged to the console.
The job submission process
l Asks the jobtracker for a new job ID (by calling getNewJobId() on JobTracker)
l Checks the output specification of the job.
l Computes the input splits for the job.
l Copies the resources needed to run the job, including the job JAR file, the configuration file and the computed input splits, to the jobtracker’s filesystem in a directory named after the job ID.
l Tells the jobtracker that the job is ready for execution (by calling submitJob() on JobTracker)
5.1.2. Job Initialization
l When the JobTracker receives a call to its submitJob() method, it puts it into an internal queue from where the job scheduler will pick it up and initialize it.
l Initialization involves creating an object to represent the job being run, which encapsulates its tasks, and bookkeeping information to keep track of the tasks’ status and progress.
l To create the list of tasks to run, the job scheduler first retrieves the input splits computed by the JobClient from the shared filesystem.
l It then creates one map task for each split.
l Tasks are given IDs at this point.
5.1.3. Task Assignment
l Tasktrackers run a simple loop that periodically sends heartbeat method calls to the jobtracker.
l As a part of the heartbeat, a tasktracker will indicate whether it is ready to run a new task, and if it is, the jobtracker will allocate it a task, which it communicates to the tasktracker using the heartbeat return value
l Before it can choose a task for the tasktracker, the jobtracker must choose a job to select the task from according to priority.(setJobPriority() and FIFO)
l Tasktrackers have a fixed number of slots for map tasks and for reduce tasks.
l The default scheduler fills empty map task slots before reduce task slots
l To choose a reduce task the jobtracker simply takes the next in its list of yet-to-be-run reduce tasks, since there are no data locality considerations.
5.1.4. Task Execution
l Now the tasktracker has been assigned a task, the next step is for it to run the task.
l First, it localizes the job JAR by copying it from the shared filesystem to the tasktracker’s filesystem.
l It also copies any files needed from the distributed cache by the application to the local disk
l Second, it creates a local working directory for the task, and un-jars the contents of the JAR into this directory.
l Third, it creates an instance of TaskRunner to run the task.
l TaskRunner launches a new Java Virtual Machine to run each task in
l It is however possible to reuse the JVM between tasks;
l The child process communicates with its parent through the umbilical interface.
5.1.5. Job Completion
l When the jobtracker receives a notification that the last task for a job is complete, it changes the status for the job to “successful.” T
l hen, when the JobClient polls for status, it learns that the job has completed successfully, so it prints a message to tell the user, and then returns from the runJob() method.

5.2. Failures
5.2.1. Task Failure
l The most common way is when user code in the map or reduce task throws a runtime exception.
n the child JVM reports the error back to its parent tasktracker, before it exits.
n The error ultimately makes it into the user logs.
n The tasktracker marks the task attempt as failed, freeing up a slot to run another task.
l Another failure mode is the sudden exit of the child JVM
n the tasktracker notices that the process has exited, and marks the attempt as failed.
l Hanging tasks are dealt with differently.
n The tasktracker notices that it hasn’t received a progress update for a while, and proceeds to mark the task as failed.
n The child JVM process will be automatically killed after this period
l When the jobtracker is notified of a task attempt that has failed (by the tasktracker’s heartbeat call) it will reschedule execution of the task.
n The jobtracker will try to avoid rescheduling the task on a tasktracker where it has previously failed.
n If a task fails more than four times, it will not be retried further.
5.2.2. Tasktracker Failure
l If a tasktracker fails by crashing, or running very slowly, it will stop sending heartbeats to the jobtracker (or send them very infrequently).
l The jobtracker will notice a tasktracker that has stopped sending heartbeats and remove it from its pool of tasktrackers to schedule tasks on.
l The jobtracker arranges for map tasks that were run and completed successfully on that tasktracker to be rerun if they belong to incomplete jobs, since their intermediate output residing on the failed tasktracker’s local filesystem may not be accessible to the reduce task. Any tasks in progress are also rescheduled.
5.2.3. Jobtracker Failure
5.3. Shuffle and Sort

5.3.1. The Map Side
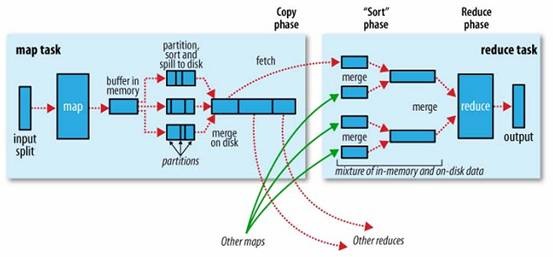
l When the map function starts producing output, it is not simply written to disk.
l Each map task has a circular memory buffer that it writes the output to.
l When the contents of the buffer reach a certain threshold size, a background thread will start to spill the contents to disk.
l Spills are written in round-robin fashion to the directories specified by the mapred.local.dir property
l Before it writes to disk, the thread first divides the data into partitions corresponding to the reducers that they will ultimately be sent to.
l Within each partition, the background thread performs an in-memory sort by key.
l Each time the memory buffer reaches the spill threshold, a new spill file is created, so after the map task has written its last output record there could be several spill files.
l Before the task is finished, the spill files are merged into a single partitioned and sorted output file.
l The output file’s partitions are made available to the reducers over HTTP.
l The number of worker threads used to serve the file partitions is controlled by the task tracker.http.threads property
5.3.2. The Reduce Side
l As map tasks complete successfully, they notify their parent tasktracker of the status update, which in turn notifies the jobtracker.
l for a given job, the jobtracker knows the mapping between map outputs and tasktrackers.
l A thread in the reducer periodically asks the jobtracker for map output locations until it has retrieved them all.
l The reduce task needs the map output for its particular partition from several map tasks across the cluster.
l The map tasks may finish at different times, so the reduce task starts copying their outputs as soon as each completes. This is known as the copy phase of the reduce task.
l The reduce task has a small number of copier threads so that it can fetch map outputs in parallel.
l As the copies accumulate on disk, a background thread merges them into larger, sorted files.
l When all the map outputs have been copied, the reduce task moves into the sort phase (which should properly be called the merge phase, as the sorting was carried out on the map side), which merges the map outputs, maintaining their sort ordering.
l During the reduce phase the reduce function is invoked for each key in the sorted output. The output of this phase is written directly to the output filesystem, typically HDFS.
来源: <Notes for Hadoop the definitive guide - 觉先 - 博客园>